Module 18 — Tool use¶
Question this module answers: How can the model act outside itself?
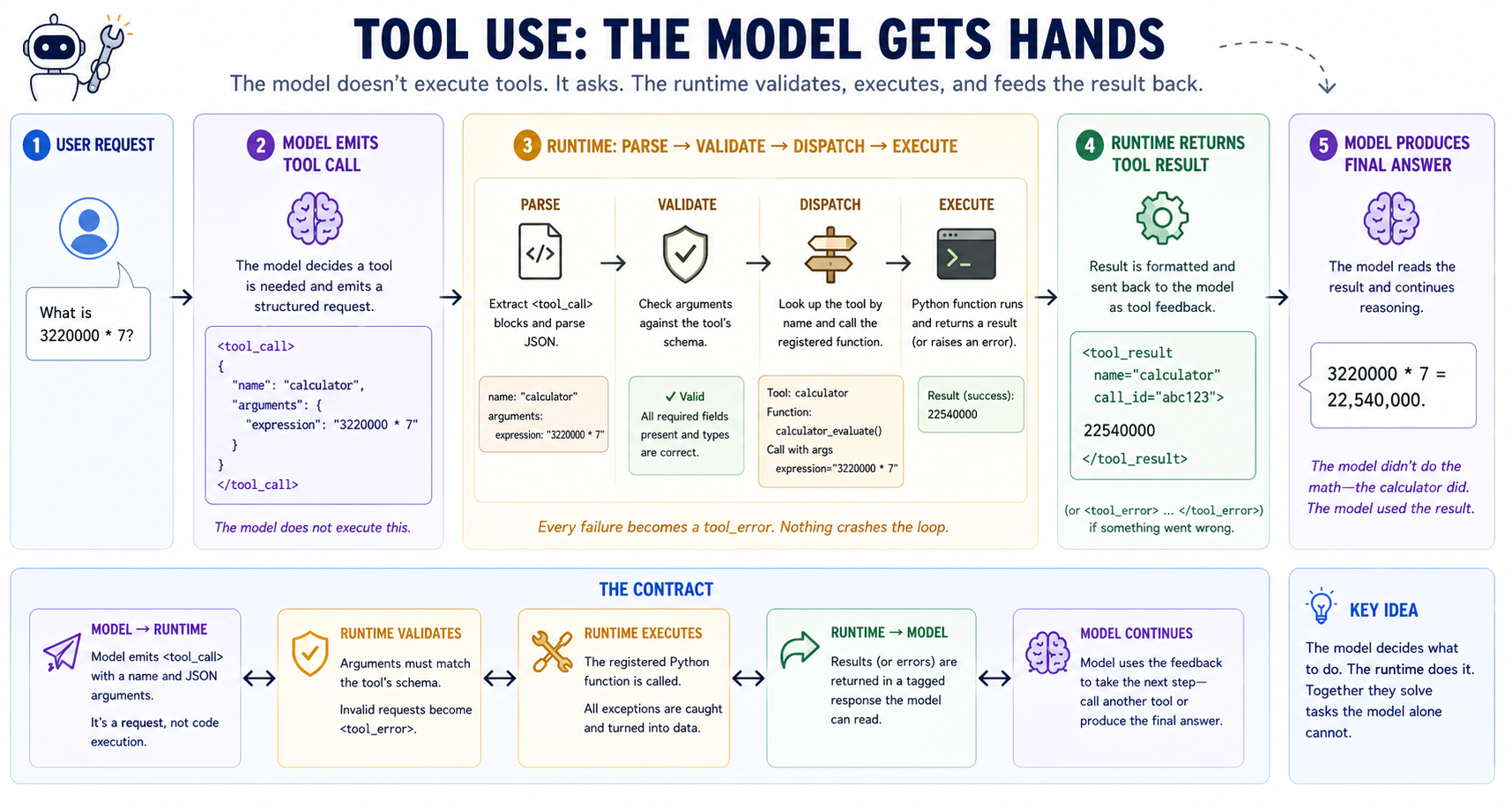
Tool use is the smallest possible architecture for "let the model affect the outside world." Define a tool as JSON, splice the schemas into the prompt, and parse tool-call blocks from the model's output.
Before you start¶
- Finish
g2c/inferencefrom 16-inference — the tool-use loop callsbackend.complete(...)to produce each model turn - Configure a ProdLM backend from 16-inference — tool calling works best with an instruction-tuned model that already understands structured tool-call formats
- Refresh JSON objects and basic regex — tool calls are JSON blocks extracted from model text
- Skim Python AST basics if you have not used
ast.parsebefore — the calculator tool uses an AST whitelist instead ofeval
Where this fits in¶
Module 16 built the interface we use to interact with the model. Module 17 extended the model's input beyond just the user prompt. In this module we will expand the ways we consume model output, to go beyond text answers and allow the model to directly take actions.
Up through Module 17, we've built the model and its surrounding assistant system to be knowledgeable. The framing has been the questions the system could answer. But knowledge isn't enough for an assistant — there are tasks that fundamentally require action:
┌──────────────────────────────────────────────────────────────────────┐
│ WHAT EVEN A 7B MODEL HANDED THE RIGHT CONTEXT CAN'T DO │
├──────────────────────────────────────────────────────────────────────┤
│ │
│ • Arithmetic on numbers it didn't memorize: │
│ - "what's 3220000 * 7?" — it'll guess wrong half the time │
│ - even Q4-quantized 70B models get long multiplications wrong │
│ │
│ • Read a file you point it at: │
│ - "summarize this 50-page PDF" — it can't *open* the PDF │
│ - even with the bytes pasted in, you've burned 50 pages of ctx │
│ │
│ • Run code: │
│ - "compute the eigenvalues of this matrix" — needs numpy │
│ - "is this regex correct?" — needs to actually run the regex │
│ │
│ • Look up information not in its training data: │
│ - "what's today's date?" — model frozen at training cutoff │
│ - "current price of AAPL?" — needs the live web │
│ │
│ • General assistant like tasks: │
│ - "set a reminder for tomorrow?" — no ability to schedule. |
│ - "book a flight for next week?" — needs external access │
│ │
│ These are the gaps tool use fills. Not by training the model on │
│ more data, not by retrieving more text — by giving it a *button* │
│ it can press to make something happen. │
│ │
└──────────────────────────────────────────────────────────────────────┘
At the end of the day, LLMs can only output text. So to let an assistant actually take action, not just answer questions, we need a structured way to turn text output into action. This module introduces a way to do exactly that.
The big idea¶
To go from model completions to external actions, we rely on the tool. The system that wraps tool usage around a model is the tool harness. Each tool in the harness represents a separate type of external action. For example there might be a web_search tool, a schedule tool and a run_python tool.
Each tool in the harness is made up of two components:
- Tool specification. This is what the model sees. Includes name, plain language description, and a structured parameter description. The specification informs the model when, why and how to use the tool.
- Tool callable. This is the external software that the tool harness runs when the model calls the specific tool. For example, for web search, the callable is responsible for actually making the queries to the search engine and returning the results.
With that framework, the assistant system has everything it needs to support external actions with arbitrary tools. As long as models follow the tool-specification convention, the individual tools are modular. The model doesn't have to learn the individual tools ahead of time. All we have to do to add a new tool is conform to the specification with enough descriptiveness that the model can figure out when to use it at prompt time.
The typical flow in a tool call involves a three way interaction between the tool harness, the model and the external callable. At a high level it looks something like this:
weather_forecasttool is registered with the tool harness- At prompt time, the harness injects the
weather_forecasttool specification (along with all other active tools) into the system prompt. - The model sees a list of tool specifications and a user prompt: "daily high San Francisco"
- The model emits a completion with a formatted tool call:
weather_forecast("San Francisco", "today") - The tool harness extracts the structured call, and dispatches it to the
weather_forecastcallable. - The callable queries AccuWeather and returns a result.
- The harness sends the tool call result back to the model.
- The model now sees the user query and the tool result, and answers the user's original question: "The high today in San Francisco is 67F"
One important point to internalize: this workflow means assistant turns are no longer synonymous with a single inference call to the model.
Tool call format¶
For the tool harness and model to coordinate, it's essential that they're aligned on the exact format for tool calls and results. If they're not, the model will not emit tool calls in a way that's recognized by the harness, and the harness will not return tool results that are understood by the model.
The exact format of the tool call and result doesn't actually matter. What matters is that the model is post-trained with high quality data to learn the exact format. This is essentially the same approach we used in 13-sft post-training to teach the model the exact assistant role formatting.
For tool call protocols, three competing conventions have emerged:
- JSON in tagged delimiters (
<tool_call>{json}</tool_call>). What this module uses. Easy to parse with a regex. - OpenAI-style structured output. The model emits a special
tool_callsarray as part of its response outside the prose. Cleaner to parse but only available on models trained for it. - Python-syntax calls (
<|python_tag|>expr). Llama 3.2's "ipython" mode. Looks like Python. We don't use this; the JSON-block approach generalizes better.
In this course we'll use the tagged JSON convention, which will emit blocks that look like this:
Why JSON inside? Because JSON has a dict and tools usually need named arguments. Positional arguments work for one-arg tools, but don't generalize to more complex cases. JSON is the lowest-friction option that's universally well-tokenized.
Tool calls are what the model writes and the harness reads. After the tool call completes, tool results are what the harness writes and the model reads back. They follow a similar formatting convention:
<tool_result name="calculator" id="call_123">
391
</tool_result>
OR
<tool_error name="calculator" id="call_123">
missing required argument: expression
</tool_error>
A few important things to note. First, tool results are freeform text; they don't have to be formatted in JSON. Because they're being read by a language model (instead of deterministic harness software), this is fine. The model will know how to interpret the text.
Second, the tag distinction matters: <tool_result> for success, <tool_error> for failures. Without the distinction, the model often parrots an error string back as if it were a successful answer.
Finally, the tool harness returns the ID that correlates with the original tool call. This matters because completions can include multiple tool calls. Without the ID, the model has no way of knowing which result matches which tool call.
The feedback contract¶
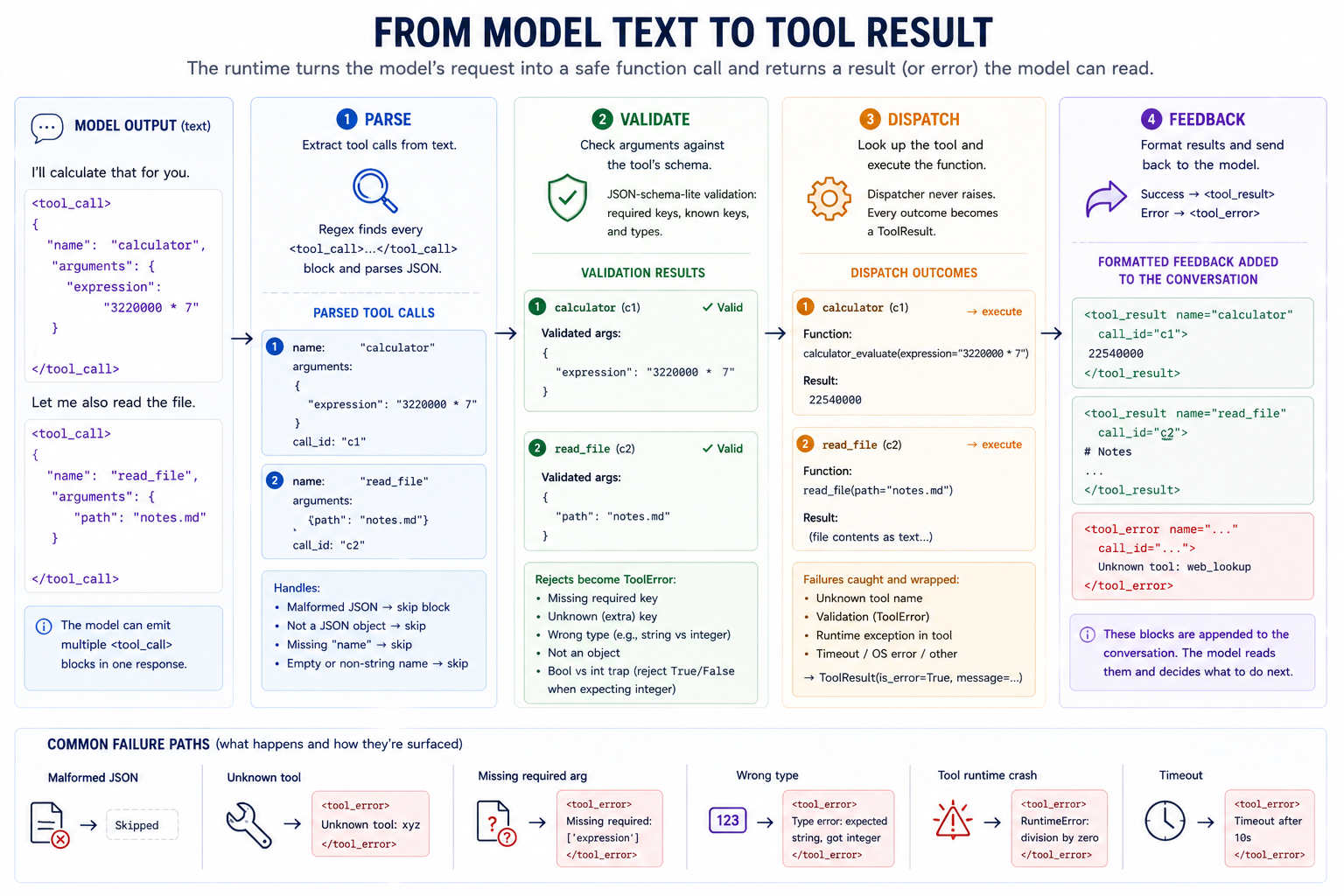 The full tool call flow in one diagram.
The full tool call flow in one diagram.
Each step in the pipeline has a precise responsibility, and each responsibility can fail in specific ways. A robust tool harness must gracefully handle, recover from, and surface errors:
┌─────────────────────────────────────────────────────────────────────────┐
│ FAILURE-MODE TABLE │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ Step What can go wrong How we surface it │
│ ──── ──────────────────── ───────────────────── │
│ parse malformed JSON skip block silently │
│ non-dict top-level skip block silently │
│ missing "name" key skip block silently │
│ non-str / empty name skip block silently │
│ │
│ validate non-dict arguments ToolError │
│ missing required key ToolError │
│ unknown extra key ToolError │
│ wrong type for value ToolError │
│ │
│ dispatch unknown tool name ToolResult(is_error=True) │
│ validation ToolError ToolResult(is_error=True) │
│ tool raised at runtime ToolResult(is_error=True) │
│ │
│ loop no more tool calls stopped_reason="no_more_calls" │
│ max_steps hit stopped_reason="max_steps" │
│ │
└─────────────────────────────────────────────────────────────────────────┘
The model may not call the tool correctly the first time. A natural response is to retry with an attempted correction. This is possible because the tool harness returns errors as text that the model can process, instead of raising errors in the harness itself. Without that, the harness would just crash on the first error.
Therefore, the tool harness has to handle multiple rounds of tool-use steps on a single query, which means we need to know when to stop. Our harness supports two stopping conditions:
- Zero tool_calls in the last completion. It's an oddly minimal contract — the model decides when it's done by simply not emitting another
<tool_call>. The alternative (an explicit "DONE" sentinel) is fragile; instruction-tuned models reliably stop calling tools. - We reach a
max_stepsthreshold. Without a cap, a confused model can loop forever, eventually overflowing the context.
Safe evaluation by construction¶
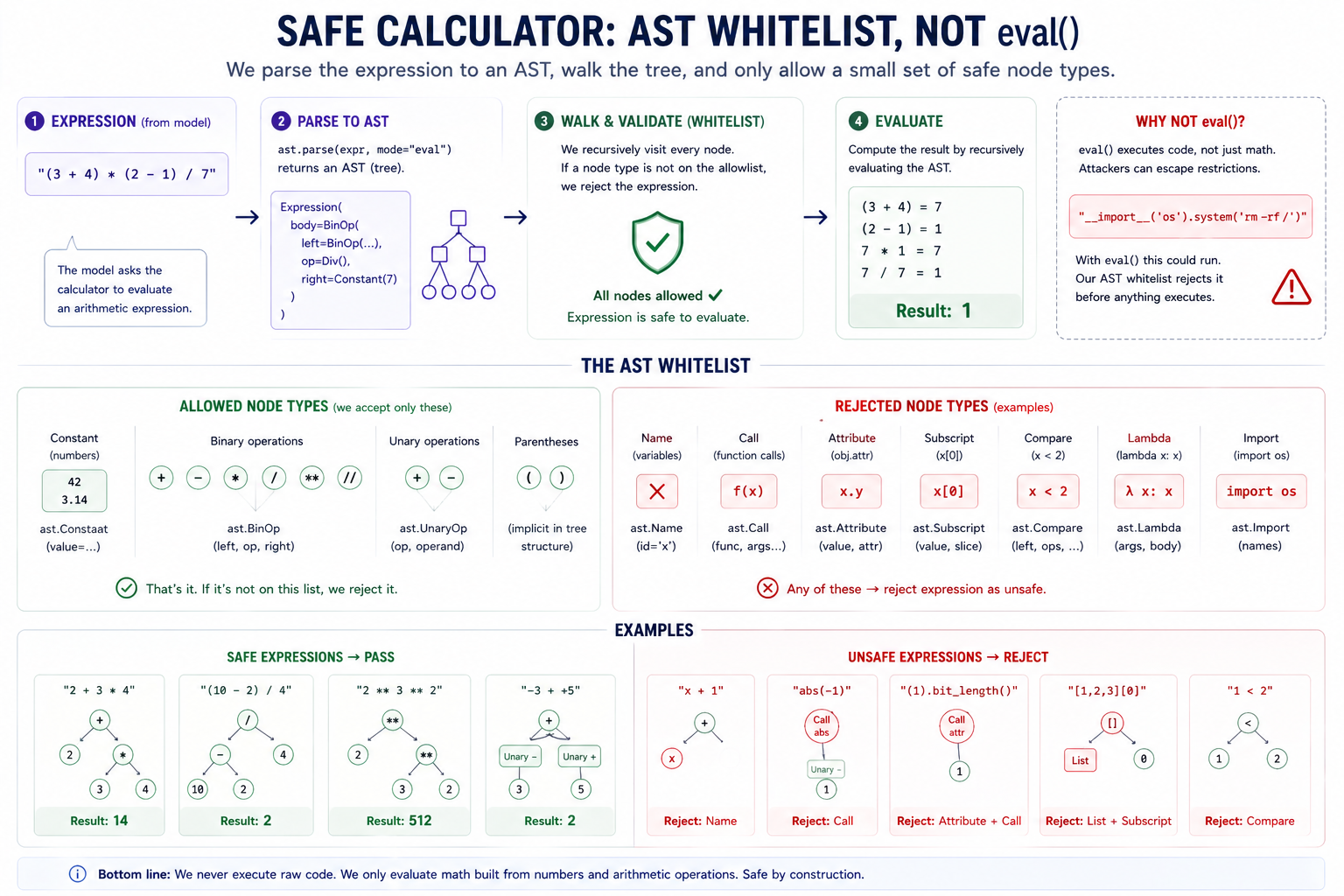 The AST-walker pattern generalizes — you'd build a safe regex evaluator, a safe template engine, a safe filter expression the same way: structurally bound the surface to exactly what you can vouch for.
The AST-walker pattern generalizes — you'd build a safe regex evaluator, a safe template engine, a safe filter expression the same way: structurally bound the surface to exactly what you can vouch for.
Unlike deterministic software, LLMs can behave in hard to anticipate ways. When we move from outputting text to directly acting, the blast radius of unpredictable behavior dramatically expands. When exposing tools to model generated input, we generally want to take a defensive posture and preemptively assume that anything the tool harness runs is potentially adversarial.
The specifics of defensive posture vary widely based on the specific tool. A datetime tool doesn't have much surface for abuse. A bash tool that executes arbitrary system commands has a huge amount of risk. The risk can also be inverted. web_search probably can't do much from its own callable. But it could return prompt injections from the public Internet. Malicious instructions in the tool result that the model might read and try to follow.
The calculator tool we're building in this module is a good case study for tool security. While arithmetic itself isn't risky, the calculator uses the Python interpreter to process the text input. There is a real risk of injecting arbitrary Python code. There are three approaches to managing risk here:
- Restricted globals +
eval(). Famously not safe — many escapes are documented in the safe-eval literature. Don't. - AST whitelist. Parse to AST, walk the tree, refuse every node not on the allowlist. What we do for the calculator. Structurally safe; the surface is what you explicitly admit.
- Subprocess + sandbox. Spawn a separate process with reduced privileges (
seccomp,nsjail, Docker, etc.). What real production code-runners use.
The calculator's safe-eval relies on "walking" the AST to check for anything that's not arithmetic:
1. parse the expression to an AST
2. walk the tree
3. allow only:
* Constant (numbers),
* BinOp (+ - * / % ** //),
* UnaryOp (+ -),
* parenthesization
4. reject every other node type by name
Every other node type is refused. The surface is what we admit; nothing else gets through. This is structurally different from eval(expr, {"__builtins__": {}}), which is a denylist (try to take away dangerous capabilities) and which has been famously broken many times. Whitelist > denylist for safety.
The "unsafe eval" that fails the AST check, with the failing node:
"x + 1" → Name(id='x') ← reject
"abs(-1)" → Call(func=Name('abs')) ← reject
"(1).bit_length()" → Attribute / Call ← reject
"[1,2,3][0]" → List, Subscript ← reject
"1 < 2" → Compare ← reject
"(lambda x:x)(1)" → Lambda, Call ← reject
"__import__('os')" → Name(id='__import__'),Call ← reject
Each is rejected at the AST walker, not because we pattern-matched the source string but because the AST node type isn't on the allowlist. The technique generalizes — you'd build a safe regex evaluator the same way (allow Concat, CharClass, Repeat; reject everything else).
The correct philosophy for tool safety is permissive parser, strict validator. This means we expect models to emit noisy, imperfectly-formatted text. Bad JSON, missing fields, and malformed tool_call blocks are not security risks. If the parser we use to extract tool calls is overly strict, we are going to suffer unnecessarily high tool-call failures. But after the inputs are parsed, we apply strict validation to what input the tool actually runs.
Concepts to internalize¶
- A tool is a callable, but the model only sees the schema. The model never executes Python. It emits text describing the call. The decoupling is what makes tool use safe(ish). Execution is the runtime's job.
- Errors are conversation. When a tool fails, the loop feeds the error back to the model and lets it try again. This single decision is responsible for most of the "robust to model mistakes" feeling.
- Safe eval is a whitelist, not a denylist. Allow only the AST nodes you can vouch for; refuse everything else.
eval()with restricted globals is famously not safe; the AST-walker pattern is structurally bounded. - Schemas are tighter than docstrings. Model output is much more reliable when the prompt includes a precise JSON schema than when it includes only a prose description. The schema gives the model a shape to fill in; prose gives it a vibe.
- The loop's stop condition is "no more tool calls." Instruction-tuned models reliably stop calling tools when they have enough context.
max_stepsis a safety net, not a feature. It exists because "the model loops forever" is a real failure mode.- Fine-tuned tool calling is a free lunch. Modern instruction-tuned open models emit
<tool_call>blocks reliably given a tool-describing prompt. Pick a model with a known tool-calling format and use it. - The parser is permissive; the validator is strict. The parser tolerates malformed blocks (silent skip) so the model isn't punished for occasional weirdness. The validator rejects malformed arguments (loud error) so the tool gets clean inputs. Different layers, different policies.
Two channels for model→tool-call communication¶
Up to this point, the loop has spoken to the model through one channel: the system prompt describes the call format, the model writes <tool_call>{json}</tool_call> into its completion, and the harness's regex parser extracts them. Call this the text-format channel. It is the lesson — building the parser, validator, and dispatch loop is what teaches the concept.
Production assistants usually use a different channel — the native channel — where the inference server (Ollama's /api/chat, OpenAI's tools=, Anthropic's tool blocks) accepts a structured tool list and returns a structured tool_calls array. The server is responsible for translating between the spec and whatever format the specific model was post-trained on (Llama's <|python_tag|>, Qwen's <tool_call>, Mistral's [TOOL_CALLS], etc.). The model is no longer instructed about the format in the prompt; it speaks its own format and the server unifies them.
┌──────────────────────────────────────────────────────────────────────┐
│ THE TWO CHANNELS │
├──────────────────────────────────────────────────────────────────────┤
│ │
│ text-format : harness builds a system prompt describing the │
│ format → model emits <tool_call>{json}</tool_call> │
│ → harness regex-extracts them │
│ │
│ PROs: backend-agnostic, transparent, the lesson │
│ CONs: model's post-training format leaks through; │
│ easy to hit format mismatch with smaller │
│ or non-tool-tuned models │
│ │
│ native : harness passes a structured tools=[...] array → │
│ server routes it through the model's own format → │
│ server returns a structured tool_calls=[...] array │
│ │
│ PROs: format problem disappears; works for any │
│ model the server supports │
│ CONs: requires a server that exposes the API; │
│ the harness becomes a thin client over it │
│ │
└──────────────────────────────────────────────────────────────────────┘
The harness in g2c/tools/loop.py supports both. run_with_tools auto-detects whether the backend exposes a chat_with_tools method and picks the native path when available; pass use_native_tools=False to force the text-format path for the same backend. The parser/validator/dispatcher pipeline runs in both — the only thing that changes is the channel by which ToolCalls reach it.
The pedagogically interesting point: the rest of the harness is unchanged. The validator still rejects bad arguments. The dispatcher still surfaces errors as is_error=True ToolResults. The stop condition is still "no tool calls in this turn." The native channel just removes one specific failure mode — the model's post-training format not matching the harness's parser regex.
What we don't cover¶
- Function-calling fine-tuning. Models like Llama 3.2 have been fine-tuned in post-training with tool-calling data — you get reliable JSON output from a properly-formatted prompt. Training your own tool-calling fine-tune would be a separate project. We rely on the model already having tool-calling instinct.
- Real JSON Schema. The full spec covers conditional schemas, references, format validators, and more. We implement the corner that gets used in practice. If you outgrow it, drop in the
jsonschemalibrary. - Production sandboxing. Real code-execution tools run in Docker or a similar isolation layer.
subprocess.runis fine for local pedagogy; it is NOT fine for a hosted service. - Streaming. Real production tool-calling streams token-by-token, parses partial JSON, and starts dispatching as soon as a complete
<tool_call>block is seen. We do the synchronous version. Conceptually identical. - Parallel tool execution. Some agentic systems dispatch all tool calls in a turn concurrently with
asyncio.gather. We dispatch sequentially. For tools whosefuncis fast (calculator, read_file), the difference is microseconds. For slow tools (HTTP search, run_python), parallelism matters in production but not for a teaching loop. - Tool-result truncation by content. A real read_file tool detects giant files and summarizes; a real run_python tool truncates large stdout. We truncate by char count only — a starting point.
What you'll build¶
Package: g2c/tools/
# base.py
@dataclass(frozen=True)
class Tool: # implemented
name: str
description: str
parameters: dict[str, Any]
func: Callable[..., Any]
@dataclass(frozen=True)
class ToolCall: # implemented
name: str
arguments: dict[str, Any]
call_id: str
@dataclass(frozen=True)
class ToolResult: # implemented
call_id: str
name: str
output: str
is_error: bool = False
class ToolError(Exception): ... # implemented
@dataclass
class ToolStep: # implemented
completion: str
tool_calls: list[ToolCall]
tool_results: list[ToolResult]
inference: InferenceResult
@dataclass
class ToolRunResult: # implemented
user_message: str
final_answer: str | None
steps: list[ToolStep]
stopped_reason: str
metadata: dict[str, Any] = field(default_factory=dict)
# registry.py
class ToolRegistry: # implemented
def __init__(self, tools=None): ...
def register(self, tool): ...
def tools(self) -> list[Tool]: ...
def names(self) -> list[str]: ...
# schema.py
def validate_arguments(tool, arguments) -> dict[str, Any]: ...
def render_tools_for_prompt(tools) -> str: ... # implemented
# parser.py
def parse_tool_calls(text) -> list[ToolCall]: ...
def format_tool_results(results) -> str: ... # implemented
# builtins.py
def calculator_evaluate(expression: str) -> float: ...
def make_calculator() -> Tool: ... # implemented
def make_read_file(*, root, max_chars=10000) -> Tool: ... # implemented
def make_web_search(*, search=None) -> Tool: ... # implemented
def make_run_python(*, timeout=10) -> Tool: ... # implemented
# loop.py
def dispatch_tool_call(registry, call) -> ToolResult: ... # implemented
def run_with_tools( # implemented (wrapper:
backend, registry, user_message, *, ..., # validate + channel select)
) -> ToolRunResult: ...
def run_text_loop( # <- your deliverable: the
backend, registry, user_message, *, ..., # complete -> parse ->
) -> ToolRunResult: ... # dispatch -> feedback loop
# _init_transcript / _grow_transcript / _build_run_result # implemented (loop plumbing)
Total scaffolded code: four function bodies — validate_arguments, parse_tool_calls, calculator_evaluate, and run_text_loop. The feedback loop is the centerpiece; the boilerplate around it (input validation, native-vs-text channel routing, transcript formatting, and ToolRunResult assembly) is provided in and around the run_with_tools wrapper, so run_text_loop stays a tight ~40-line call → parse → dispatch → feed-back cycle.
How to run the tests¶
Tests live in tests/test_tools.py. Initial state: 84 passed, 105 failed.
source .venv/bin/activate
pytest tests/test_tools.py # all module-18 tests
pytest tests/test_tools.py -x # stop at first failure
pytest tests/test_tools.py -k Validate # validator tests
pytest tests/test_tools.py -k Parse # parser tests
pytest tests/test_tools.py -k Calculator # calculator tests
pytest tests/test_tools.py -k RunWithTools # loop tests
pytest tests/test_tools.py -k Integration # full-pipeline smoke
pytest tests/test_tools.py -v # verbose
Exercises¶
To launch the exercise notebook run:
If at any point you want to archive the work in your current notebook and restart fresh:
The live section defaults to ProdLM because tool calling needs instruction-following behavior. You can switch the model-selection cell to MODEL_SELECTION = "course" for your strongest course artifact, preferring -DPO, then -SFT, then base. Concrete artifact base names follow the same fallback.
- Calculator reliability. Measure when the model calls the calculator and whether it is correct.
- Read + compute. Chain file reading with calculation.
- Malformed outputs. Stress-test parser and validator recovery.
- Python tool. Use a sandboxed Python tool for a small data task.
- Custom tool. Register one tool from your own work context.
- Tool ablation. Compare no-tool, tool-available, and tool-missing setups.
- Citation enforcement. Check whether final answers are grounded in actual tool results.
- Deliverable CLI. Build a small tool-using chat loop.
- Tools post-mortem. Document what worked, where it broke, and what to improve next.
Pitfalls to expect¶
- Parser/format mismatch. The model's emitted tool-call format must exactly match what the parser expects. If you see calls in text but zero parsed calls, align the template first.
- Permissive parser, strict validator. Parsing should skip malformed blocks; validation should reject unknown tools, missing args, wrong types, and extra keys.
- Regex greediness. Tool-call extraction needs non-greedy matching and
DOTALL, or multiple/multiline calls collapse into one bad block. - Arguments one level down. Dispatch
obj["arguments"], not the whole parsed JSON object. - Unsafe Python execution. Never use
shell=Trueforrun_python; pass a list of arguments and keep timeouts/cwd explicit. - Tool-call loops.
max_stepsis a safety cap, not a reasoning strategy. Multi-step recovery becomes Module 19's agent loop. - Final answer plus tool call. Decide which wins. The course loop treats a parsed tool call as authoritative and continues.
M-series notes¶
This module is comfortable on every M-series Mac. Practical considerations:
- Inference happens via
OllamaBackend(orLocalTransformerBackendfor the from-scratch model — but the from-scratch model isn't trained for tool calling, so it won't follow the schema). All Module 16 caveats apply: first call is slow, steady-state matches the model's parameter count. - Tool execution latency. The calculator is microseconds;
read_fileis microseconds for small files;web_searchdepends on your backend (the stub is microseconds; a real DuckDuckGo / Tavily call is ~1 second);run_pythonis the slowest (subprocess startup + Python init is ~50–200ms on M-series). - Subprocess startup cost.
subprocess.run([sys.executable, "-c", ...])pays ~50-200 ms in Python startup. Ifrun_pythonis called frequently, the total wall time is dominated by startup. A more advanced runner reuses a long-lived Python child process viasubprocess.Popen+ line-based protocol; out of scope here, but worth knowing about. - Context length. Each step appends to the transcript. A 5-step run with verbose tool results can easily reach 4–8k tokens. Llama 3.2's 128k context is comfortable; smaller-context models would need careful pruning of past turns. Module 19 will introduce conversation memory management.
- No special memory considerations for tool execution itself. The tool runtime is pure Python plumbing. The model's inference is the memory-hungry part, and that's the same as Modules 16/17.
Reading¶
Primary:
- Schick, Dwivedi-Yu, Dessì et al., "Toolformer: Language Models Can Teach Themselves to Use Tools" (NeurIPS 2023). The paper that named the genre. The key contribution is bootstrapping — using the model itself to label tool-call positions in pretraining text, then fine-tuning on those labels. Read §3 (the self-supervised data construction) — that's the durable idea. The empirical results in §4 are the canonical "tool-using LM beats vanilla LM on factual tasks" demonstration.
- Anthropic, "Tool use" docs (claude.ai docs). Practical, current. Walks through Claude's
<invoke>format, schema requirements, multi-turn tool use, and parallel tool calls. Read alongside the OpenAI function-calling docs to see the two industry-standard formats. - OpenAI, "Function calling" docs (platform.openai.com). The other industry standard. Read for contrast to Anthropic — same concept, different shape (structured
tool_callsarray vs XML-tagged JSON in prose). Either format works; the differences are surface-level.
Secondary:
- Patil, Zhang, Wang, Gonzalez, "Gorilla: Large Language Model Connected with Massive APIs" (NeurIPS 2024). Specialized fine-tuning for API selection at scale. Skim §3 — the construction of an API zoo and the bench against generalist models is the interesting bit. Useful as a "what does it look like when tool selection itself becomes the bottleneck" reference.
- Yao, Zhao, Yu et al., "ReAct: Synergizing Reasoning and Acting in Language Models" (ICLR 2023). The "Thought / Action / Observation" interleaving that we'll build in Module 19. Read it now to see what's coming; the loop in this module is the substrate ReAct sits on.
- Anthropic, "Building effective agents" (Dec 2024). A practical taxonomy of agentic patterns: prompt chains, routing, parallelization, orchestrator-workers, evaluator-optimizer, and the ReAct agent. Module 18's loop is the simplest agentic pattern; Module 19 builds toward the others.
Optional:
- Qin, Liang, Ye et al., "ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs" (ICLR 2024). Gorilla's spiritual successor — much larger API zoo, depth-first vs breadth-first search over API combinations. Skim if you want to see how production tool-using systems handle hundreds of tools.
- Park, O'Brien, Cai et al., "Generative Agents: Interactive Simulacra of Human Behavior" (UIST 2023). Uses tools and memory to simulate a small town of agents. Skim for the architectural overview — the way they decompose memory, planning, and reflection generalizes well beyond the simulation use case.
- Liu, Li, Du et al., "AgentBench: Evaluating LLMs as Agents" (ICLR 2024). A benchmark suite covering tool use, web browsing, OS interaction, and game-playing. Useful as a "what gets evaluated" reference if you want to systematically measure your agent's capability later.
Deliverable checklist¶
- All tests in
tests/test_tools.pypass: 172 tests, all green. - Ollama running with a tool-calling-capable chat model.
ollama listshows your chosen model. - Notebook:
notebooks/solutions/18-tools.ipynb. - Tool-use post-mortem (Exercise 9) in 3-4 paragraphs. The main deliverable.
- You can explain — out loud, without notes — why errors are surfaced as
ToolResult(is_error=True)instead of raised exceptions. - You can explain — out loud, without notes — why AST-walking is structurally safer than
eval()with restricted globals. - You can explain — out loud, without notes — what the loop's stop condition is and why "no more tool calls" works as a signal.
- You can explain — out loud, without notes — why the validator must reject
boolwhen expectingintornumber.