Module 04 — Tokenization¶
Question this module answers: How do we turn text into model input?
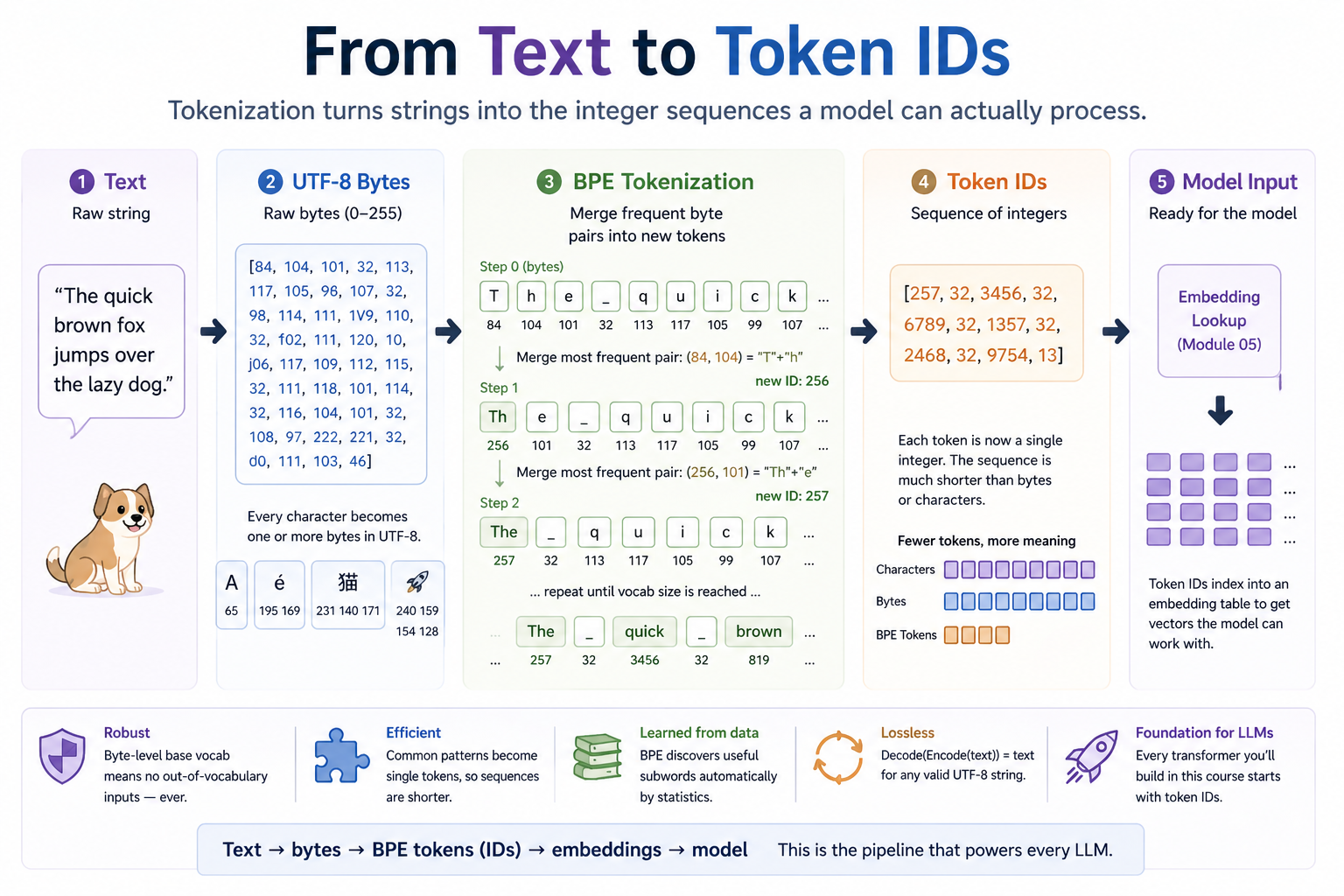
The whole pipeline that turns "The quick brown fox..." into the integer list a model actually sees. Finding and merging the most frequent adjacent byte pairs is the entire BPE algorithm.
Before you start¶
- Review
- Python
bytesand UTF-8 if either feels unfamiliar —bytesis a sequence of integers in[0, 256);- UTF-8 is variable-width (ASCII 1 byte, common European 2, emoji 4)
- Python
- Run
./datasets.sh --tinyto prepare the datasets used in the notebook./datasets.sh --smallif you want to do the optional exercise
Where this fits in¶
The course up to this point has worked with numbers. Real LLMs work with text. Tokenization is the bridge between the two — the function that turns "The quick brown fox" into [464, 2068, 7586, 21831] and back. Every input to every transformer in production goes through a tokenizer first; every output comes from one in reverse. It's the first thing you'd build in an LLM pipeline and the last thing in inference.
There are three genuinely different ways to do this, with very different tradeoffs:
Vocab size Sequence length OOV?
─────────────────────────────────────────────────────────
Character-level: tiny long no
Word-level: huge short yes (rare words → <UNK>)
Subword (BPE): tunable medium no
Character-level (or byte-level) is robust but produces sequences too long to fit in a context window. Word-level produces short sequences but explodes vocab size and silently drops out-of-vocabulary words. Subword tokenization — specifically byte-pair encoding (BPE) and its close cousins WordPiece and SentencePiece — splits the difference. Common substrings ("the", "ing", "ation") become single tokens; rare or novel inputs fall back to smaller pieces; nothing is ever truly out-of-vocabulary because the base vocab covers every possible byte.
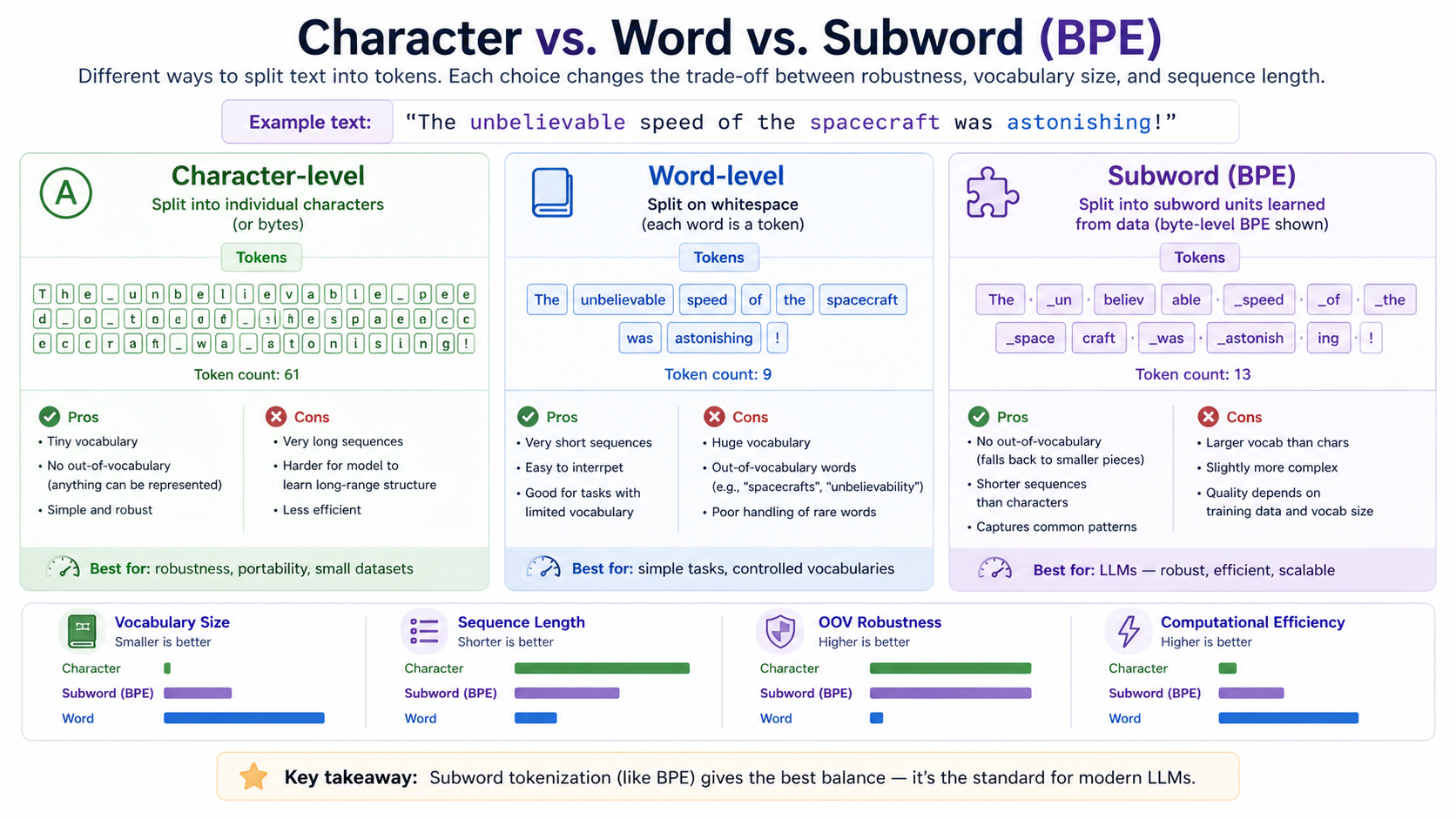 The same sentence, three tokenizers. Character-level keeps the vocab tiny but blows out the sequence; word-level shortens the sequence but balloons the vocab and chokes on
The same sentence, three tokenizers. Character-level keeps the vocab tiny but blows out the sequence; word-level shortens the sequence but balloons the vocab and chokes on "unbelievable" if it wasn't seen during training; subword/BPE finds the middle by carving common substrings ("_un", "believ", "_speed") into single tokens and falling back to pieces only for the rare bits. Every modern LLM picks the third column.
Modern LLMs all use BPE-family tokenizers. GPT-⅔/4, Llama, Mistral, Qwen — same algorithm, different training data. Module 04 has you build it.
The big idea¶
BPE training is a single greedy loop:
- Start with a base vocabulary — every possible byte (256 entries).
- Encode your training corpus as a list of byte IDs.
- Find the most frequent adjacent pair of IDs.
- Mint a new ID for that pair and replace every occurrence in the corpus.
- Record the merge (so you can replay it later on new text).
- Repeat until you hit the target vocab size.
Worked through on a tiny corpus:
Train BPE on the corpus "the the the":
Initial bytes:
ids = [116, 104, 101, 32, 116, 104, 101, 32, 116, 104, 101]
─── ─── ─── ──── ─── ─── ─── ──── ─── ─── ───
t h e ' ' t h e ' ' t h e
Most common pair: (116, 104) = 't' + 'h' (count 3)
Mint new ID 256. merges[(116, 104)] = 256.
After merge 1:
ids = [256, 101, 32, 256, 101, 32, 256, 101]
─── ─── ─── ─── ─── ─── ─── ───
th e ' ' th e ' ' th e
Most common pair: (256, 101) = 'th' + 'e' (count 3)
Mint new ID 257.
After merge 2:
ids = [257, 32, 257, 32, 257]
─── ─── ─── ─── ───
the ' ' the ' ' the
Most common pair: (257, 32) = 'the' + ' ' (count 2)
Mint new ID 258. ...
 Encoding replays the merges in learned order. Decoding is just byte concatenation. Training is just repeating the loop until the target vocabulary size is reached.
Encoding replays the merges in learned order. Decoding is just byte concatenation. Training is just repeating the loop until the target vocabulary size is reached.
Every merge shortens the sequence and adds one entry to the vocabulary. The merges learned earliest (lowest IDs) capture the most common patterns; later merges capture progressively more specific patterns. The final tokenizer is just the table of merges, applied left-to-right by priority.
Encoding new text is the same idea in reverse: take the byte sequence, repeatedly find the lowest-ID merge that applies, and apply it. Stop when no learned merge fits any adjacent pair.
Decoding is trivial: every ID in the vocabulary maps to a fixed byte sequence (the base 256 IDs map to single bytes; learned IDs map to the concatenation of their parents' bytes). Concatenate, decode UTF-8, done.
The whole thing is ~50 lines of Python. The cleverness is in the choice — BPE produces a tokenization where common patterns become single tokens by virtue of statistics, no linguistic knowledge required. It's a tiny algorithm with outsized practical impact.
Special tokens¶
"Special tokens" are reserved strings that mean something to the model/runtime instead of just ordinary prose. Later modules need tokens for document boundaries, chat roles, and tool events:
<|endoftext|> separates documents/stories during pretraining
<|system|> starts a system message
<|user|> starts a user message
<|assistant|> starts an assistant message
<|tool_call|> starts a structured tool request
<|tool_result|> starts a tool result
<|end|> ends one message/event
<|pad|> optional batching filler
These must be atomic. If the text contains <|assistant|>, the tokenizer should emit one reserved ID, not the byte sequence for <, |, a, ... and not a set of BPE pieces. Atomic special tokens matter because Module 13 onward will train on chat/tool formats where the marker itself is part of the interface contract.
In this repo, BPETokenizer() is byte-only by default for the tiny BPE exercises. Use BPETokenizer.with_course_special_tokens() when creating reusable course tokenizer artifacts. Those reserved IDs live immediately after the 256 byte IDs, and learned BPE merges start after them. BPE training treats special tokens as barriers, so it does not learn a merge that consumes <|endoftext|> plus a neighboring word.
Concepts to internalize¶
- Tokens vs. token IDs. A token is a byte sequence (e.g.,
b'the'). A token ID is the integer the tokenizer assigns to it (e.g.,258). The vocab is the bidirectional map. - Base vocab is byte-level. Every byte 0–255 has its own ID. This guarantees no out-of-vocabulary inputs, ever — every UTF-8 string can be encoded somehow, even if the encoding falls back to raw bytes for unfamiliar characters.
- Merges are ordered and priority-encoded by ID. Earlier merges have lower IDs. At encode time, lower-ID merges win — they're the most frequent patterns and should be applied first.
- Training is one merge step repeated.
train_step()does the conceptual work once: count pairs, choose the most frequent pair, mint the new ID, merge the sequence, and updatemerges/vocab.train()is just the scaffolded outer loop plus progress reporting. - The greedy merge rule has a subtlety. When
_mergesees[1, 1, 1]and the merge target is(1, 1), the result is[99, 1], not[99, 99]. The middle1is consumed by the first match and isn't available for a second. Left-to-right, non-overlapping. - Lossless round-trip is structural. As long as every byte ends up in the vocab and merges are concatenations of their parents,
decode(encode(text)) == textfor any UTF-8 string. This is not a property you have to test for at every input — it's guaranteed by the construction. - Vocab size is a tunable knob. Bigger vocab → more compression on the training distribution → shorter sequences but more parameters in the embedding table. Real LLMs use 32k–200k range.
- Special tokens are reserved interface markers. They encode atomically and are not ordinary BPE merges. Use them for document boundaries, chat roles, and tool-call events.
What we don't cover¶
- Performance on big corpora. A naive implementation re-counts all pairs on the full sequence every iteration: O(n) per merge × thousands of merges = slow on real corpora. For training on TinyShakespeare it's fine. If you wanted to train on Wikipedia you'd need to keep counts incrementally.
What you'll build¶
Package: g2c/tokenizer/
class BPETokenizer:
merges: dict[tuple[int, int], int] # learned: pair → new ID
vocab: dict[int, bytes] # ID → bytes representation
special_tokens: tuple[str, ...] # optional atomic control tokens
def train(self,
text: str,
vocab_size: int, ...): ... # Pre-implemented loop
def train_step(self,
ids: list[int],
new_id: int): ...
def encode(self, text: str) -> list[int]:
def decode(self, ids: list[int]) -> str:
About 50 lines of real implementation in total.
For later modules and durable tokenizer artifacts, create the course-token variant:
How to run the tests¶
Tests live in tests/test_tokenizer.py. Initial state: 23 passed, 47 failed. The construction and train-validation tests pass; the BPE algorithm tests fail with NotImplementedError until you fill in the TODOs.
source .venv/bin/activate
pytest tests/test_tokenizer.py # run all module-04 tests
pytest tests/test_tokenizer.py -x # stop at first failure
pytest tests/test_tokenizer.py -k pair # only pair-count tests
pytest tests/test_tokenizer.py -v # verbose
Exercises¶
To launch the exercise notebook run:
If at any point you want to archive the work in your current notebook and restart fresh:
The notebook has the exact prompts, inspection tables, and artifact cells.
- Pair counts and merge behavior. Predict tiny BPE pair counts and non-overlapping merges.
- Train BPE on a tiny corpus. Connect
train_step,merges, andvocabby hand. - Encode, decode, and round-trip. Verify lossless byte-level tokenization.
- Special tokens. Confirm course control tokens stay atomic.
- Vocab size vs compression. Compare token counts across vocab sizes.
- Inspect learned tokens. Look at early, late, frequent, and long learned tokens.
- Pre-tokenization demo. See how boundary choices shape possible merges.
- Mini milestone. Save reusable tokenizer artifacts for later modules.
Pitfalls to expect¶
-
Off-by-one in pair counting. A list of length
nhasn - 1adjacent pairs, notn.range(len(ids) - 1)or azip(ids, ids[1:])style is the cleanest. -
The overlap trap in
_merge. Naively iterating withfor i in range(len(ids))and matching at every position will double-consume the middle element of[1, 1, 1]. Use awhileloop with explicit index advancement, or aforloop with askip-nextflag, but make sure you only consume each element once. -
Mutable state across training steps.
train_stepshould add one entry toself.mergesand one entry toself.vocab, not replace either dictionary. (The tests assume you start from a fresh tokenizer per test, so this is more of a real-world concern.) -
encodeinfinite loop. If your encode logic finds a merge to apply but doesn't actually shorten the list, you'll loop forever. Always verify the new list is shorter than the old. -
Special-token off-by-one errors. If you reserve special tokens, the first learned merge is not ID 256 anymore. It starts at
tokenizer.base_vocab_size. Tests cover both byte-only and course-special-token paths. -
Merging across a special token. A special token is a boundary. Do not learn a merge like
(<|endoftext|>, "The"); that would turn an interface marker into an ordinary corpus-specific subword. -
UTF-8 decode of partial sequences. If you ever construct an ID list that doesn't correspond to a valid UTF-8 byte stream,
bytes.decode("utf-8")raises. Useerrors="replace"for robustness — but a correctencode/decoderound-trip should never trigger this.
M-series notes¶
This module is pure CPU. No GPU, no MPS — every operation is pointer chasing through Python data structures.
- Training on a small corpus takes seconds.
- Training on TinyShakespeare (~1MB) at
vocab_size=8192takes 1–5 minutes on a typical M-series machine. Most of the time is spent recounting all pairs after each merge — that's where the naive implementation pays its O(n²) cost. - Going above 10M characters is infeasible with the Python-native
g2ctokenizer. The module includes a wrapper for a much faster Rust-based tokenizer. This is what the notebook uses to train TinyStories and g2c. Even with that, expect tens of minutes for those corpora.
Reading¶
Primary:
- Karpathy, "Let's build the GPT Tokenizer" (YouTube, ~2h). The single best resource on this topic. Builds essentially this same tokenizer, then extends it to the GPT-2 regex-split version.
- Karpathy,
minbperepo (https://github.com/karpathy/minbpe). The reference implementation. Worth reading after you've finished your own.
Secondary:
- Sennrich, Haddow, Birch, "Neural Machine Translation of Rare Words with Subword Units" (2016). The original BPE paper. Short and readable.
- Radford et al., "Language Models are Unsupervised Multitask Learners" (GPT-2 paper), §2.2. Where byte-level BPE for LMs was introduced.
Optional:
- Kudo & Richardson, "SentencePiece" (2018). A different subword tokenizer used by Llama and others. The differences from BPE are small but pedagogically interesting.
Deliverable checklist¶
- All tests in
tests/test_tokenizer.pypass. -
notebooks/solutions/04-tokenizer.ipynb: trained on a real corpus at three vocab sizes; token count + compression ratio table; printed top-20 / bottom-20 of learned vocab at the largest size; demonstrated atomic course special tokens. -
artifacts/tokenizers/ShakespeareTokenizer/: savedtokenizer.json, sampleids.uint32, andmanifest.json. - Optional: after running
./datasets.sh --smallor./datasets.sh tinystories, enable and saveStoryTokenizerand/orG2CTokenizer. The logicalg2csource prefers the full corpus when present and falls back to the small corpus. - You've inspected the learned vocabulary and can point to a few subword tokens that are obviously frequent patterns (
"the","ing"," of", etc.) and a few that are more specific to your corpus. - You can explain — out loud, without notes — why
[1, 1, 1]merging(1, 1)produces[99, 1], not[99, 99].