Module 08 — Multi-head attention¶
Question this module answers: How does attention specialize?
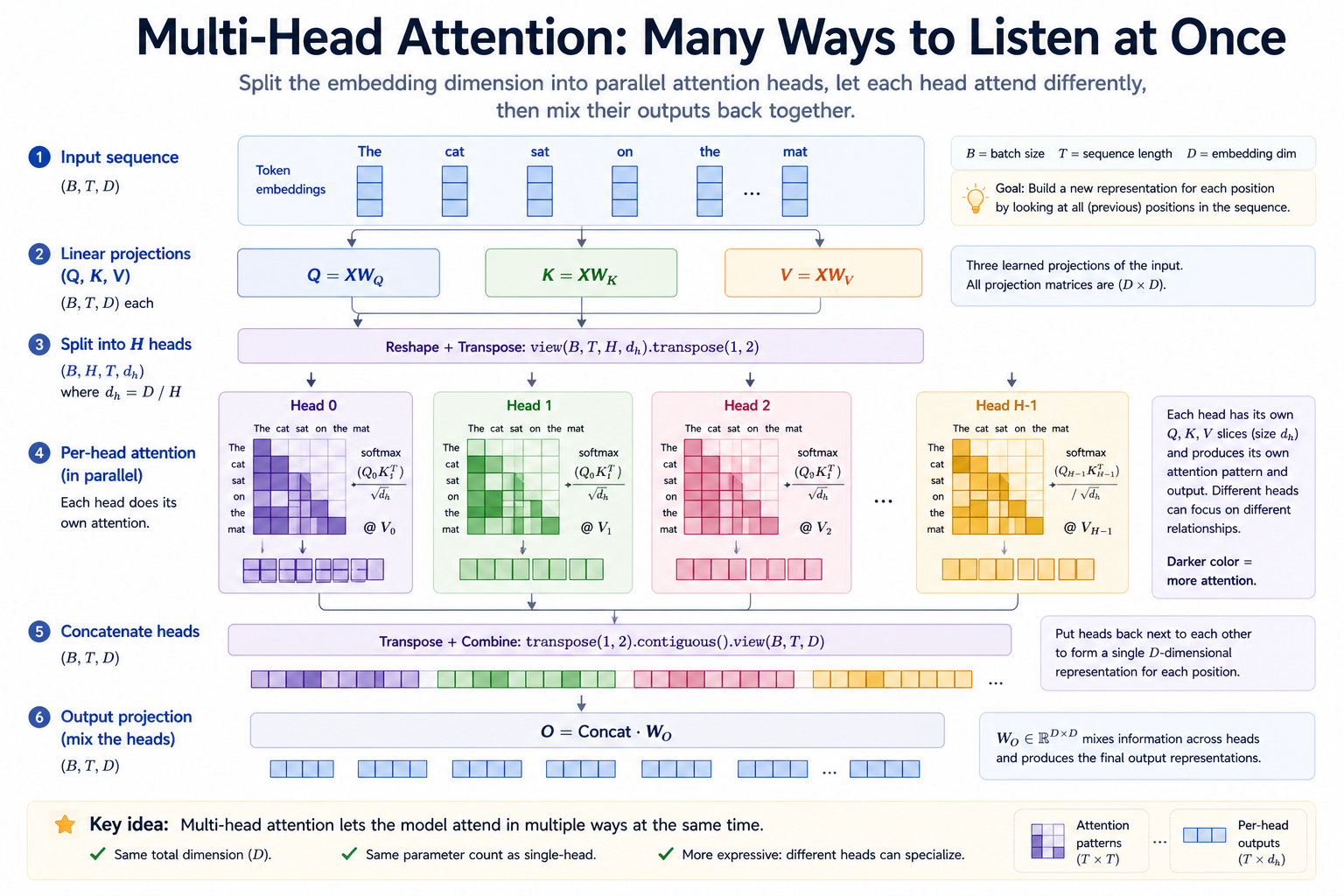
This week is short on content. Almost everything is already in place from the last lesson. Review the scaled dot-product and softmax machinery from the previous module. The conceptual move is "split D into H slots and run H copies of attention in parallel"; the engineering move is "do that with one matmul, not H of them."
Before you start¶
- Review 07-attention — multi-head is one structural change on top of single-head attention
- Finish
g2c/attentionfrom 07-attention — Module 08 extends the same package; M07's prerequisites cover the underlying deps - Finish
g2c/nnfrom 03-nn,g2c/embeddingsfrom 05-embeddings, andg2c/tokenizerfrom 04-tokenizer — exercise 3 trains a tiny LM end-to-end and uses all three
Where this fits in¶
Module 07's single-head attention works, but it has a structural limitation: the Q/K/V projections compress everything one query wants to ask about into a single D-dimensional vector. If the model wants to attend differently for different reasons — e.g., one query direction for syntactic dependencies, another for coreference, another for adjacency — a single head must overload all of those onto the same D channels.
We address this limitation by introducing multiple heads into a single attention model. The headline empirical result, due to Vaswani et al. and substantially deepened by Anthropic's transformer-circuits work, is that different heads spontaneously specialize during training. Some heads learn to attend to the previous token. Some learn to attend to syntactic dependencies. Some implement induction — copying a previous occurrence of the current token's predecessor. The mechanism doesn't prescribe specialization. Specialization falls out of the training dynamics when you give the model multiple independent attention slots.
The big idea¶
The whole module is one structural change — splitting D into H slots — and one matching detail change — √head_dim instead of √D.
Multi-head attention gives the model H parallel attention channels, each operating in its own head_dim = D/H subspace. Each head computes its own Q, K, V, scores, softmax, and weighted value mix independently. The H per-head outputs are concatenated and passed through a final output projection that mixes the heads' findings back into a coherent D-dim representation.
Single-head (Module 07) Multi-head (Module 08)
x ─► Wq ─► Q (T, D) x ─► Wq ─► Q (T, D) ─► view+T ─► (H, T, d_h)
x ─► Wk ─► K (T, D) x ─► Wk ─► K (T, D) ─► view+T ─► (H, T, d_h)
x ─► Wv ─► V (T, D) x ─► Wv ─► V (T, D) ─► view+T ─► (H, T, d_h)
scores = QK^T/√D (T, T) scores = QK^T/√d_h (H, T, T)
mask + softmax mask + softmax (H, T, T)
mixed = wV (T, D) mixed = wV (H, T, d_h)
concat = T+view (T, D)
out = Wo(mixed) (T, D) out = Wo(concat) (T, D)
Same operations on both sides. Multi-head just adds an H axis to everything in the middle. Crucially, the parameter shapes of the projections — Wq, Wk, Wv, Wo — are all (D, D) in both versions. The split into heads is structural, not parametric.
The reshape, in detail¶
The single most important line in this module is:
view(B, T, H, head_dim) reinterprets the last dim D as two dims (H, head_dim). After this view, position t's embedding has been sliced into H consecutive chunks of size head_dim:
embedding_dim = D = 8, num_heads = H = 4, head_dim = 2
Before view: [a0, a1, a2, a3, a4, a5, a6, a7] (D=8)
After view: [[a0, a1], [a2, a3], [a4, a5], [a6, a7]] (H=4, d_h=2)
head 0 head 1 head 2 head 3
The transpose(1, 2) then swaps T and H so heads are the leading batch-like dim:
Why this order? Because the next operation is q @ k.transpose(-2, -1), and PyTorch's batched matmul treats all dims except the last two as batch dims. With H in the leading batch slot, the matmul produces one (T, T) score matrix per head independently. With H not in the leading slot, the matmul would mix queries from different heads together — which is the wrong thing.
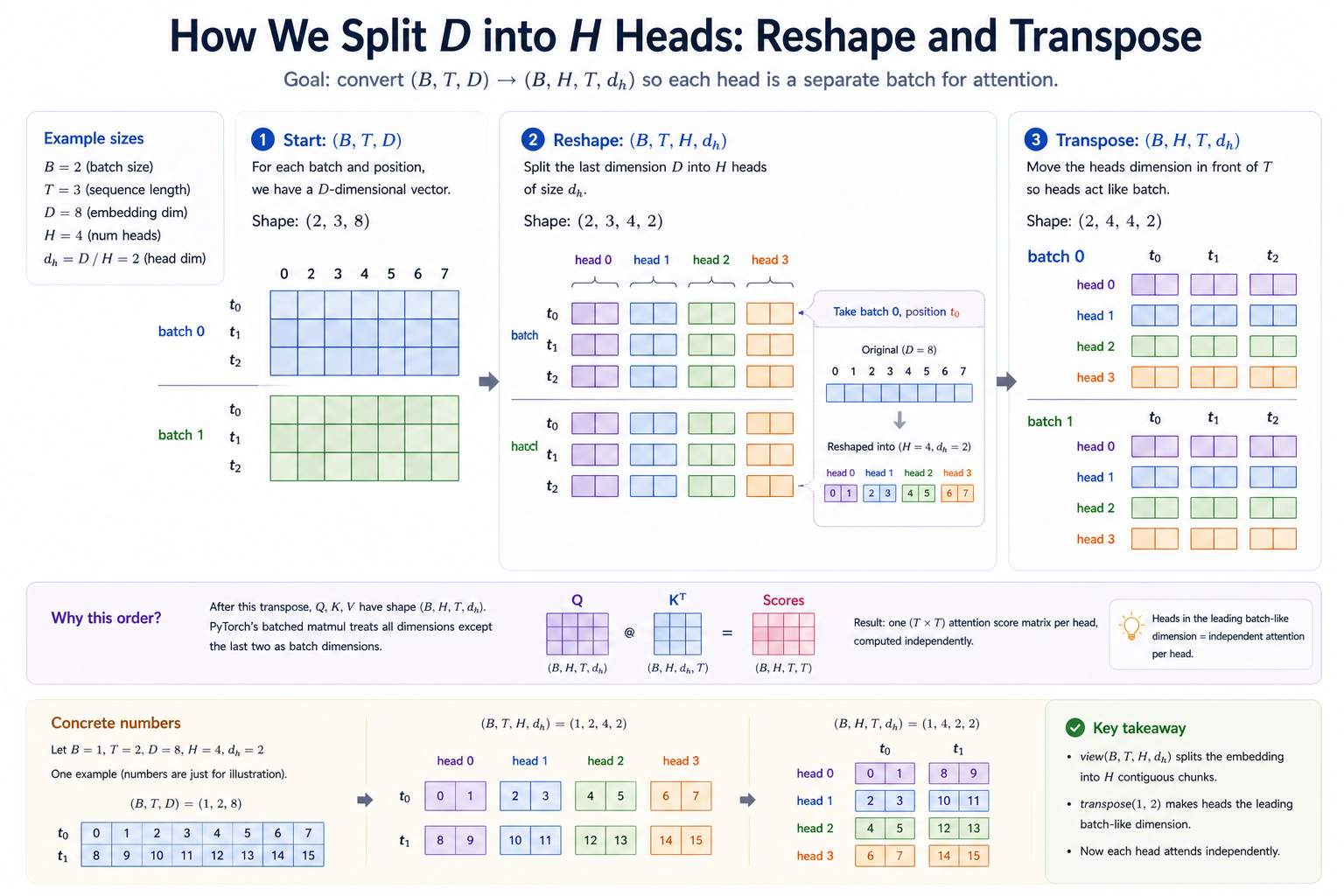 The two-line
The two-line view + transpose is doing all the work that a Python loop over heads would otherwise do. Internalizing which dim ends up where, and why the matmul that follows treats H as just another batch dim, is the entire engineering content of multi-head attention.
One projection plus reshape ≠ H independent projections¶
Naively, you might implement multi-head attention as H independent (D, head_dim) linear layers per role:
# WRONG (or rather, *expensive and equivalent for inference,
# strictly less expressive for training*):
q_per_head = [Linear(D, head_dim) for _ in range(H)]
qs = [q_per_head[h](x) for h in range(H)] # H independent matmuls
The implementation in this module uses one Linear(D, D) followed by a reshape:
# RIGHT (and standard):
q = self.q_proj(x) # one matmul, (B, T, D)
q = q.view(B, T, H, head_dim).transpose(1, 2)
These are not equivalent. The (D, D) projection has a full set of cross-head parameters — entries W[i, j] where the row i belongs to input dim i and the column j lands in some head's d_h slot. The H-independent version only has H × (d_h × d_h) parameters arranged on a block-diagonal; the cross-block parameters are zero.
Practically speaking the single (D, D) projection is strictly more expressive (it can learn the block-diagonal structure if it wants to) and strictly cheaper (one big matmul beats H small ones on modern hardware). It's the better choice on both axes, which is why the literature has converged on it. The "multi-head" part is in how the output of the projection is interpreted, not in how the projection itself is parameterized.
The √ scaling changes: √head_dim, not √D¶
In Module 07, the scaling factor was 1/sqrt(D) because each dot product was over a D-dimensional vector pair. In multi-head attention, each per-head dot product is over a head_dim-dimensional pair, so the scaling factor is 1/sqrt(head_dim).
This is the single most common multi-head bug. Symptom: training is slower than expected, attention weights are flatter than expected, gradients are sluggish — but nothing crashes. The scores are under-scaled by a factor of sqrt(H), so the softmax stays in a high-temperature regime where attention is nearly uniform.
The output projection becomes load-bearing¶
In Module 07's single-head version, the output projection Wo was mostly ceremonial — it could be folded into the value projection without changing the model's expressiveness.
In multi-head, Wo is genuinely necessary. After concatenating the H per-head outputs, you have a (B, T, D) tensor in which the first head_dim channels came from head 0, the next from head 1, and so on. Without a learned mixing step, those channels would propagate forward as siloed "head 0 said this, head 1 said that" without ever interacting. Wo is the parameter matrix that lets the heads contribute to one another's outputs.
You can think of the full multi-head attention as: "compute H independent attention patterns in parallel, then learn how to combine their outputs." Wo is the "combine" step.
Heads specialize during training¶
This is the empirical surprise: when you train a transformer with multi-head attention, individual heads often learn to specialize on specific kinds of patterns. The phenomenon is studied carefully by Elhage et al. (Anthropic transformer circuits) and Olsson et al. (induction heads). A few canonical specializations:
- Previous-token heads. A head that puts almost all weight on position
t-1. Useful for copying immediate context. - Induction heads. A head that, given the pattern
... A B ... A, puts weight on the position right after the previousA— predictingB. This is the mechanism behind much of in-context learning. - Syntactic heads. Heads that attend along grammatical dependencies (subject ↔ verb, modifier ↔ noun).
- Copy heads. Heads that pass values through almost unchanged — a "do nothing here, let the residual stream carry me" head.
You won't see these in your tiny model from Module 10 with high fidelity — you need many more parameters and training data — but the mechanism is set up here. The visualization exercise (exercise 4) will let you LOOK at attention patterns after training and see whether any heads have learned anything interpretable.
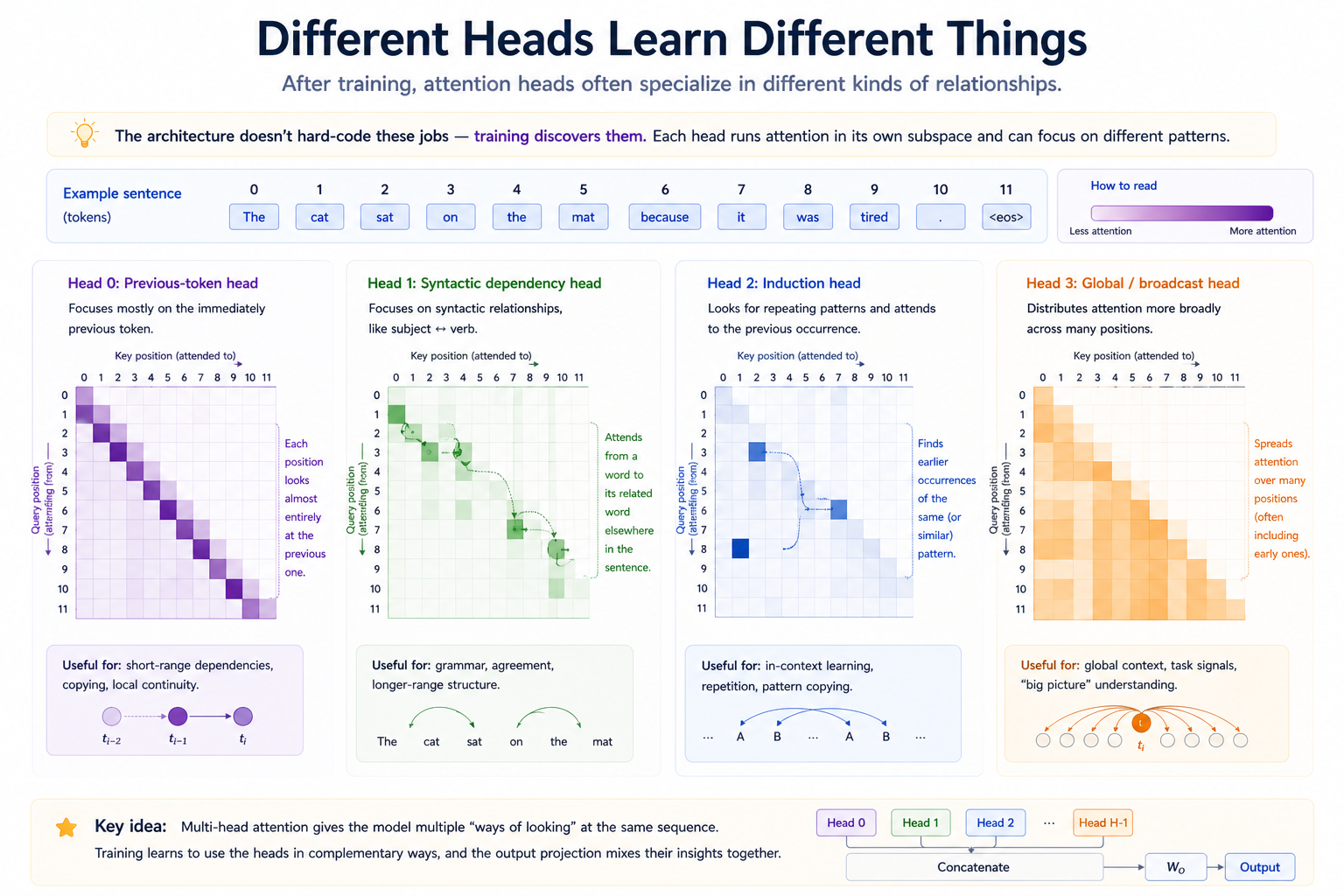 Multi-head attention's empirical payoff isn't visible from the math — it shows up only when you train and look. With H heads available, the optimizer is free to use one for previous-token copying, another for syntactic dependencies, another for induction, etc., and it tends to do so. Single-head attention has to commit one set of weights to ALL of these jobs simultaneously; multi-head attention can specialize and recombine via W_O.
Multi-head attention's empirical payoff isn't visible from the math — it shows up only when you train and look. With H heads available, the optimizer is free to use one for previous-token copying, another for syntactic dependencies, another for induction, etc., and it tends to do so. Single-head attention has to commit one set of weights to ALL of these jobs simultaneously; multi-head attention can specialize and recombine via W_O.
Concepts to internalize¶
- Multi-head = H copies of single-head, run in parallel in disjoint subspaces. Math is identical; only an
Haxis is added. - The split is structural, not parametric. All four projections remain
(D, D). The split happens inview/transpose. - Reshape, then transpose, then matmul. The order matters: heads must end up in a leading batch-like dim before scoring, then move back to position-adjacent before the final concat.
- Scale by
√head_dim, not√D. The most common multi-head bug. - The output projection is now load-bearing. It mixes the H per-head outputs back into a coherent representation.
- Heads specialize empirically. Different heads learn different attention patterns — the structural reason multi-head outperforms single-head with the same parameter budget.
- Total parameter count is independent of
H. Splitting D into 8 heads instead of 1 doesn't change the parameter count one bit; it changes only the structure of the computation.
What we don't cover¶
- Multi-query / grouped-query attention (one K/V head shared across many Q heads — the optimization that makes long-context inference cheap). Out of scope.
- FlashAttention's IO-aware tiling. The math is the same; only the memory access pattern changes.
- Cross-attention (Q from one source, K/V from another — used in encoder-decoder transformers). The course is decoder-only.
What you'll build¶
Package: g2c/attention/
class MultiHeadAttention(Module):
embedding_dim: int # D
num_heads: int # H
head_dim: int # D // H
causal: bool
q_proj: Linear # (D, D)
k_proj: Linear # (D, D)
v_proj: Linear # (D, D)
out_proj: Linear # (D, D)
def __init__(self, embedding_dim: int, num_heads: int, *, causal: bool = True): ... # implemented
def parameters(self) -> Iterable[torch.Tensor]: ... # implemented
@staticmethod
def causal_mask(seq_len: int, device=None) -> torch.Tensor: ... # implemented
def forward(self, x: torch.Tensor) -> torch.Tensor: ... # SCAFFOLDED
def attention_weights(self, x: torch.Tensor) -> torch.Tensor: ... # SCAFFOLDED
Roughly 20 lines of real code split across the two scaffolded methods. The conceptual delta from Module 07 is small — most of the lesson is in the reshape and the √head_dim change.
How to run the tests¶
Tests live in tests/test_multi_head_attention.py. Initial state: 13 passed (construction + causal_mask + parameter counts), 17 failed.
source .venv/bin/activate
pytest tests/test_multi_head_attention.py # run all module-08 tests
pytest tests/test_multi_head_attention.py -x # stop at first failure (recommended)
pytest tests/test_multi_head_attention.py -k forward # only the forward tests
pytest tests/test_multi_head_attention.py -v # verbose
Exercises¶
To launch the exercise notebook run:
If at any point you want to archive the work in your current notebook and restart fresh:
The notebook carries the detailed prompts, plots, and training cells.
- Verify the reshape. Check by hand that each head sees the intended slice.
- Reshape order matters. Break and restore the canonical head layout.
- Train at multiple head counts. Compare
H = 1, 4, 8at fixed embedding size. - Visualize per-head patterns. Plot one heatmap per head after tiny training.
- Parameter counts. Confirm head count changes structure, not parameter count, at fixed
D.
Pitfalls to expect¶
-
Scaling by √D instead of √head_dim. The single most common multi-head bug. Training is sluggish; attention weights are too flat; gradients propagate weakly. Nothing crashes; the failure is subtle.
-
Reshape order:
(B, T, head_dim, H)instead of(B, T, H, head_dim). The shape is the same after view, but heads end up "seeing" interleaved slices of the embedding (positions 0, H, 2H, ... instead of 0..head_dim-1). Will silently produce a different model. -
Forgetting
.transpose(1, 2)after the reshape. Without it,Tis in the leading batch-like position andHis in the position-adjacent position, so the next matmul will mix queries from different heads. -
Forgetting
.contiguous()before the finalviewto concatenate heads. PyTorch will raise an exception. Insert.contiguous()or use.reshape(...). -
Mask polarity backwards (same as Module 07).
causal_maskreturns True ABOVE the diagonal — the positions to BLOCK. The(T, T)mask broadcasts naturally over(B, H, T, T)scores. -
Implementing per-head with
Hindependent linear layers. Works mathematically, but is H× slower (H matmuls instead of 1) and strictly less expressive (block-diagonal projections instead of full ones). The standard idiom is one(D, D)projection plus reshape. -
Returning
attention_weightsof shape(B, T, T)instead of(B, H, T, T). The "averaged over heads" version drops the per-head visualization that motivates exposing this method at all. Keep the H dim. -
embedding_dimnot divisible bynum_heads. The constructor raisesValueErrorfor this, but if you bypass it (or computehead_dimwith integer division and silently lose dims), shapes will mismatch downstream. Don't silence the check.
M-series notes¶
This module is light on compute.
- Exercise 3's training comparison (3 runs at fixed
D = 64) is a few hundred steps each on a small corpus; under a couple minutes total on CPU. - Exercise 4's per-head visualization is a single forward pass on one sentence — milliseconds.
- The clean notebook uses
experiment_device = "auto"for the training comparison. The plotted attention weights are moved back to CPU before Matplotlib sees them, because Matplotlib cannot plot MPS tensors directly.
Reading¶
Primary:
- Vaswani et al., "Attention Is All You Need" (2017), §3.2.2. Multi-head attention is defined in two equations and one paragraph. This is the section to read. The illustration in figure 2 (right panel) shows the structure.
- Karpathy, "Let's build GPT: from scratch, in code, spelled out" (YouTube). The multi-head section walks through this same construction in PyTorch — same reshape idiom, same √head_dim scaling.
Secondary:
- Elhage et al., "A Mathematical Framework for Transformer Circuits" (Anthropic, 2021). The introductory and "what do heads compute" sections reframe multi-head attention as
Hindependent read-write operations on the residual stream. The framework is illuminating even if you skim the late sections on circuits. - Olsson et al., "In-context Learning and Induction Heads" (Anthropic, 2022). The empirical study of how induction heads emerge during training. Pairs nicely with the visualization exercise — gives a sense of what a "real" specialized head looks like.
Optional:
- Kim & Vaswani, "Multi-Query Attention" and follow-ups on grouped-query attention. The optimization that makes long-context inference cheap by sharing K and V across multiple query heads. Out of scope for this course but worth knowing exists.
Deliverable checklist¶
- All tests in
tests/test_multi_head_attention.pypass. - Notebook:
notebooks/solutions/08-multi-head-attention.ipynb. Train tiny LMs atnum_heads = 1, 4, 8with fixedembedding_dim = 64and matched training budgets; plot validation loss curves on the same axes. - Notebook: per-head attention visualization on a chosen sentence using one of the trained models —
Hheatmaps in a grid. - You can explain — out loud, without notes — why the scaling factor is
√head_dimrather than√D, and what specifically goes wrong if you use√D. - You can explain — out loud, without notes — why the reshape
view(B, T, H, head_dim).transpose(1, 2)is the right operation, and what would go wrong withview(B, T, head_dim, H).