Module 11 — Sampling and decoding¶
Question this module answers: How do we use a model to produce text?
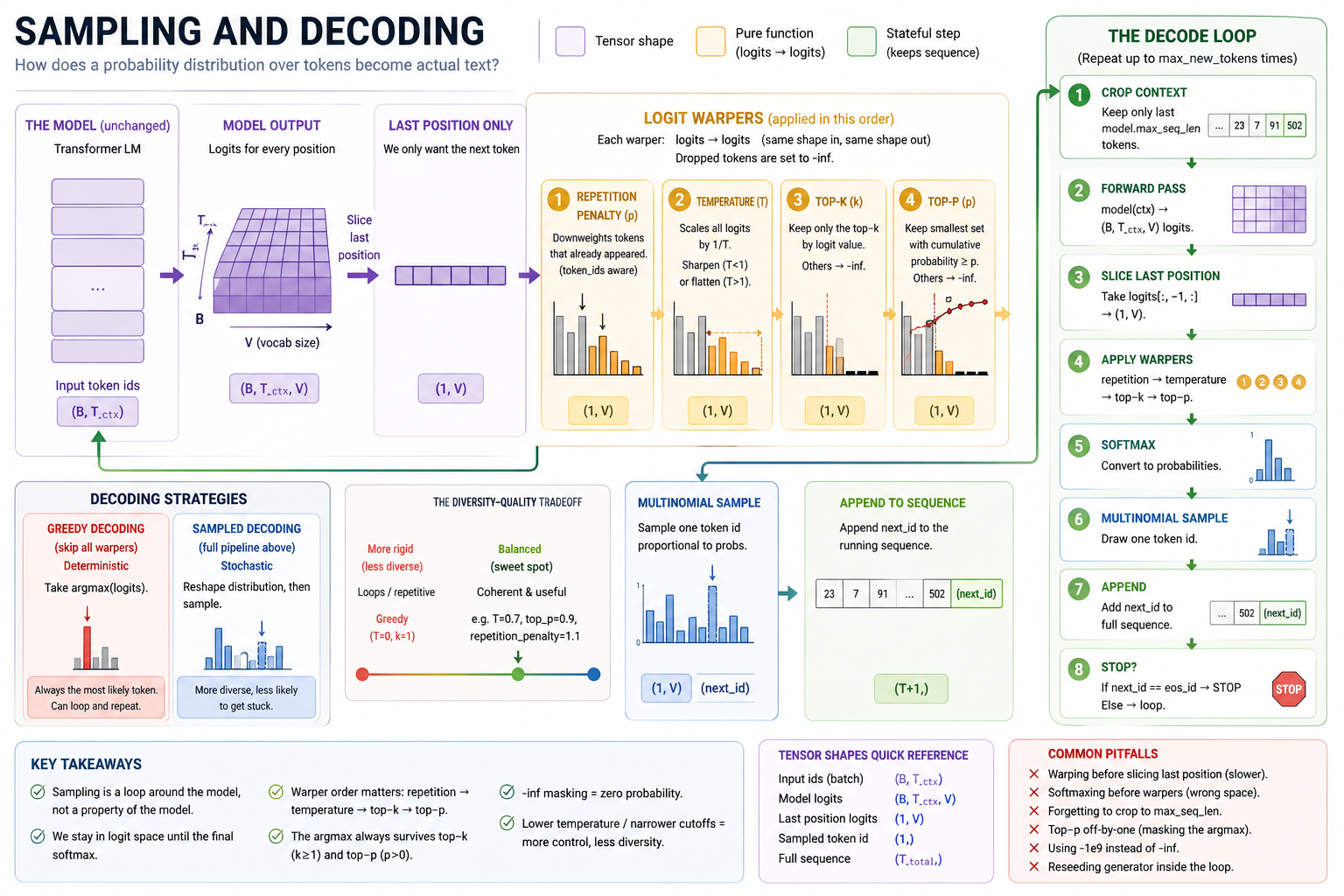
You trained a model in Module 10, and now you need to actually generate text from it. Sampling is just the loop that calls the model. Four small "warper" functions reshape the model's native distribution before each draw. Internalizing those four warpers and the eight-step loop is the module.
Before you start¶
- Review
- 09b-pretraining (logits)
- PyTorch Primer
- Finish
g2c/transformer(09-transformer-block)- At least one trained model from 10-tinyllm notebook (
ShakespeareLM,StoryLM, orTinyLLM), or run./baselm.shand explicitly loadBaseLMfor comparison
- Run
./baselm.sh(optional) if you want to run the notebook with a more powerful model
Where this fits in¶
After Module 10 you have a model trained on next-token cross-entropy. Calling the model returns logits — but logits aren't text. The transformation from a distribution over tokens to actual sampled output is what this module is about.
The simplest and most obvious approach is greedy decoding. Always pick the token corresponding to the argmax of the logits. But that often produces output like:
Greedy decoding tends to loop. The model emits the most-likely token, that token shifts the context one step, but the new context is similar enough to the old that the model's prediction stays nearly the same, and the model keeps emitting the same token (or short cycle) forever. This is a structural property of small models in particular. Larger models tend to loop less, but never stop looping entirely.
Another simple and obvious approach is pure random sampling. Multinomial draw from the native softmax. This produces the other extreme:
Native softmax puts nonzero mass on every possible token, including thousands of long-tail tokens that are essentially unrelated to the prefix. Once in a while one of them gets sampled, and the output derails. Both naive approaches are brittle for generating text, especially over long ranges.
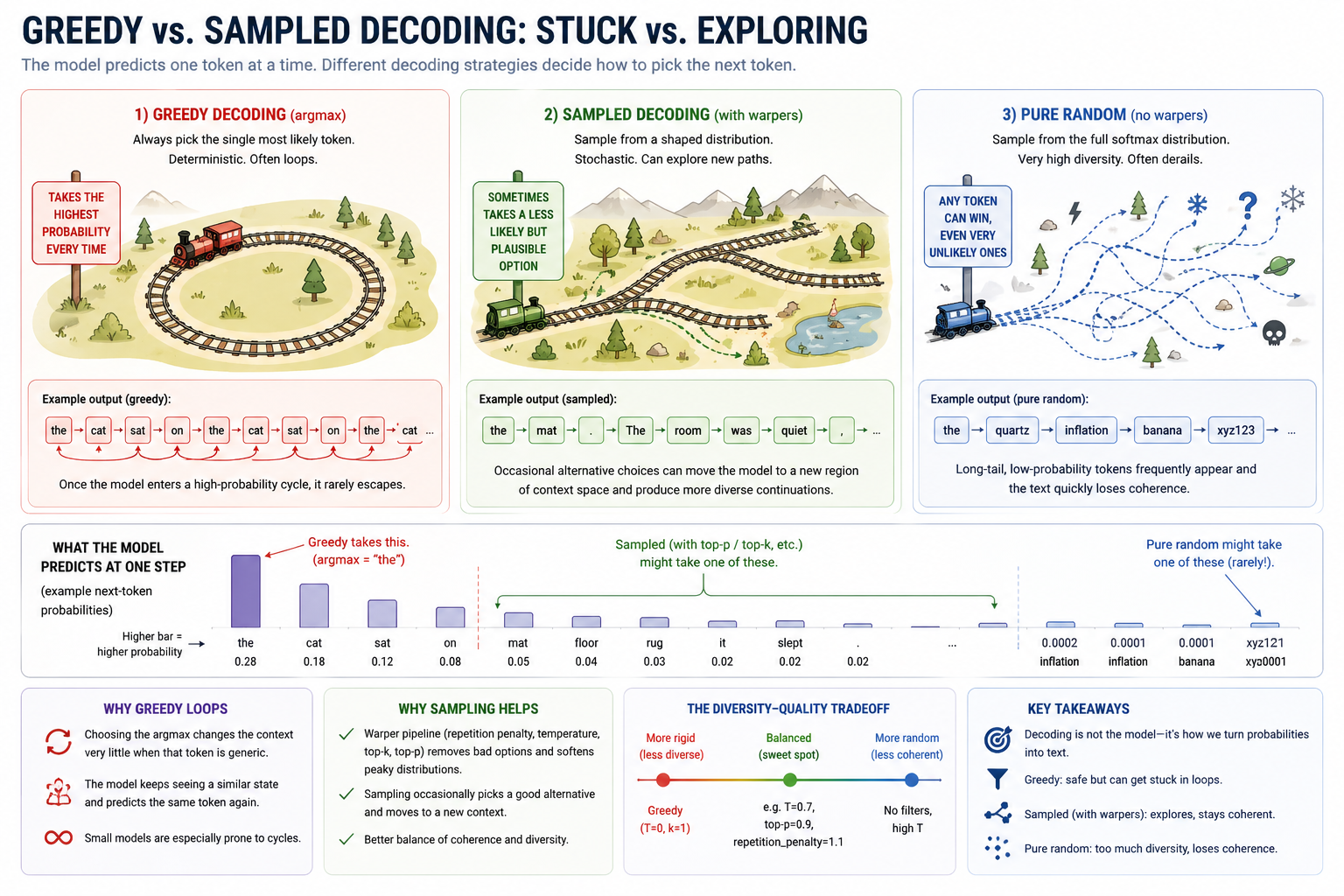 Greedy and pure-random are the two failure modes. The warpers shape the model's native distribution into something that's neither argmax-locked nor long-tail-derailed.
Greedy and pure-random are the two failure modes. The warpers shape the model's native distribution into something that's neither argmax-locked nor long-tail-derailed.
The big idea¶
The fix is a small pipeline of logit "warpers" that reshape the distribution before sampling — the model's native distribution gets sharpened (temperature), the long tail gets cut off (top-k or top-p), and tokens that already appeared get nudged down (repetition penalty). We take those re-weighted logits, and use softmax to get a "clean" probability distribution to sample the next token from.
Logit warpers as a pipeline¶
Every warper has the same signature:
Same shape in, same shape out. Dropped tokens are replaced with -inf (so softmax(-inf) = 0 cleanly), surviving tokens keep their original logit values, and the warper does no normalization. This is what lets the warpers compose: any subset, in any order, can be chained together, and the final softmax handles the renormalization.
┌──────────────────────┐ ┌────────────────────┐
│ repetition_penalty │ ──►│ temperature │ ──►
│ rescales prior tokens│ │ divides everything │
└──────────────────────┘ └────────────────────┘
┌───────────────────┐ ┌────────────────────┐
──►│ top_k_filter │ ──►│ top_p_filter │ ──► softmax
│ -inf below rank k │ │ -inf below CDF p │
└───────────────────┘ └────────────────────┘
The order matters but the contract doesn't change: each box takes a logit tensor and returns a logit tensor.
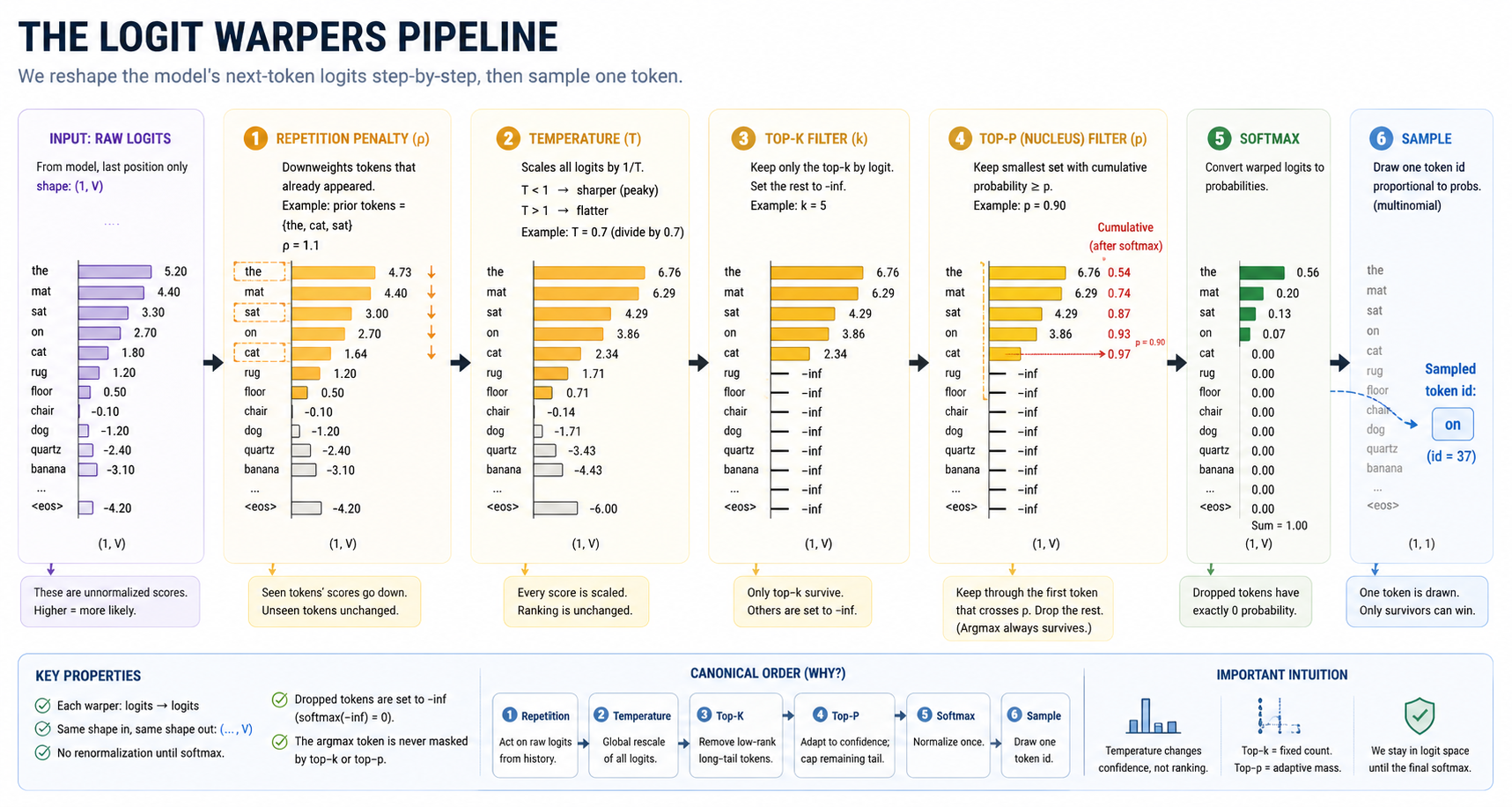 The four warpers are pure functions of
The four warpers are pure functions of (logits, args) — none of them maintain state, none of them peek at each other, and the order in which they apply is the lesson.
Temperature: a single-knob sharpness control¶
Temperature is the simplest warper and the most common knob for generation:
After softmax:
T → 0⁺ probs collapse onto argmax (one-hot)
T = 1 the model's native distribution
T → ∞ probs flatten toward 1/V (uniform)
Temperature never reorders tokens. Whatever was most likely stays most likely; whatever was least likely stays least likely. Temperature is a monotone reweighting of probabilities. Therefore temperature can't rescue a model whose native argmax is consistently wrong.
 Higher temperature sampling produces sequences that tend to seem more spontaneous. Lower temperature tends to be more predictable.
Higher temperature sampling produces sequences that tend to seem more spontaneous. Lower temperature tends to be more predictable.
Top-k: a hard cutoff on count¶
The model's softmax has nonzero probability on every one of V tokens. With V = 50_000, the long tail — very-low-probability tokens — has noticeable collective mass. Sampling from the full distribution occasionally produces a long-tail draw that derails the sequence. Top-k caps the surviving set at the k highest-probability tokens:
After softmax, the dropped tokens have probability 0 and the surviving k are renormalized to sum to 1. The argmax is always one of the survivors; top-k can never reorder rankings.
Native: [3.2 2.7 2.1 1.9 1.5 ... -0.4] (V tokens)
▲ ▲ ▲ ▲ ▲ ▲
top-3 │ │ └─────┴── below threshold
▼ ▼ ▼
After k=3: [3.2 2.7 2.1 -inf -inf ... -inf]
The downside: a fixed k doesn't adapt to the model's confidence. If the top token has 95% of the mass, top-50 keeps 49 essentially-zero distractors. If the model is uncertain across hundreds of plausible continuations, top-50 cuts off many reasonable choices. Top-p was designed to fix exactly that.
Top-p (nucleus): an adaptive cutoff on mass¶
Top-p sorts the probabilities descending and keeps the smallest prefix of the CDF whose mass reaches p:
Sort probabilities descending.
Compute cumulative mass.
Keep the smallest prefix whose cumulative mass >= p.
Set everything outside that prefix to -inf.
Concretely, with p = 0.9:
Native: [0.60 0.20 0.10 0.05 0.03 0.02 ...]
Cumulative: [0.60 0.80 0.90 0.95 0.98 1.00 ...]
▲ ▲ ▲ ─── crosses 0.9 here; KEEP through here
│ │ │
KEEP KEEP KEEP, drop everything after
After p=0.9: [0.60 0.20 0.10 -inf -inf -inf ...]
When the model is confident, the prefix is small (one or two tokens). When the model is uncertain, the prefix expands to include more candidates. The size of the surviving set adapts automatically.
One important note: the implementation should always keep the first token after the cumulative threshold mass >= p is crossed. Otherwise a high-confidence argmax could result in no token.
 The reason top-p tends to read as "smarter" than top-k in practice: it spends its budget where the budget actually matters.
The reason top-p tends to read as "smarter" than top-k in practice: it spends its budget where the budget actually matters.
Repetition penalty: discouraging loops¶
Small models loop. "the cat sat on the cat sat on the cat sat on the..." If X is the most likely next token, then it often remains the most likely choice at the second step, the third step, and so on. The repetition penalty (Keskar et al., "CTRL", 2019) is the standard defense:
for every token id that appeared in the prior context:
if that token's logit is positive: divide by penalty
if that token's logit is negative: multiply by penalty
Both branches push probability down. The asymmetric formula ensures the rescaling is always a penalty, regardless of the sign of the logit. Penalty 1.0 is no-op; penalty 1.05 to 1.3 is the typical range; penalty >= 2 often kills repeats entirely (usually not a good thing).
prior tokens: [..., 5, 7, 5, 2, ...] tokens 5, 7, 2 are seen
Native logits: [a₀, a₁, a₂, a₃, a₄, a₅, a₆, a₇, a₈, ...]
▲ ▲ ▲
penalize penalize penalize
a₂ a₅ a₇
(2) (5) (7)
Two design points to internalize:
- Apply before temperature. Repetition penalty operates on raw logits; temperature uniformly scales whatever logits it sees. Apply repetition penalty first so the penalty isn't itself amplified by the temperature divide.
- Penalty applies to token ids, not positions. A token id seen once long ago is penalized just as much as one seen recently. Some variants weight by recency or count; CTRL doesn't, and we follow CTRL.
The decode loop¶
The full per-step recipe:
┌────────────────────────────────────────────────┐
│ ONE DECODE STEP │
└────────────────────────────────────────────────┘
full_ids ──► crop to model.max_seq_len ──► (1, T_ctx)
│
▼
model(ctx)
│
▼
logits[:, -1, :] (1, V)
│
▼
apply_repetition_penalty(logits, full_ids, ρ)
│
▼
apply_temperature(logits, T)
│
▼
top_k_filter(logits, k)
│
▼
top_p_filter(logits, p)
│
▼
softmax(logits) (1, V)
│
▼
multinomial(probs, 1)
│
▼
append next_id to full_ids
│
▼
stop if next_id == eos_id, else loop
A reordering that looks equivalent but isn't:
WRONG (warp logits at every position, not just last):
logits = model(ctx) # (1, T, V) — every position
...
logits = warp(logits)
last_logits = logits[:, -1, :] # slice after warps
Mathematically yields the same answer but does T-fold more work,
per step for no reason. Always slice FIRST.
WRONG (softmax before warpers):
probs = softmax(model(ctx)[:, -1, :])
probs = apply_temperature(probs, T) # ??? doesn't compose
...
All of the warper functions are written for logits, not probabilities.
Stay in logit space until the very last softmax.
 Most miswirings of this loop produce code that looks correct — output still appears, no exceptions raised. But the output will be miscalculated and produce subtly incorrect results.
Most miswirings of this loop produce code that looks correct — output still appears, no exceptions raised. But the output will be miscalculated and produce subtly incorrect results.
The diversity-vs-quality tradeoff¶
Sampling controls trade off two qualities you can't maximize together:
- Diversity: how surprising / non-deterministic the output is.
- Quality: how locally-coherent / on-prompt the output is.
Sliding to the right (raising temperature, removing top-k/top-p) gets more diverse and more chaotic output. Sliding to the left (lowering temperature, narrowing top-k/top-p) gets more confident but boring (and at the limit, looped) output.
There is no globally-correct knob position. The canonical "balanced" setting in the open-LM community is roughly temperature=0.7, top_p=0.9, with no top-k and a small repetition penalty. Real applications tune these per-task: code generation usually wants low temperature and tight top-p. Creative writing wants higher temperature and looser top-p. A chat assistant wants something in the middle.
The exercise set will sweep these knobs against your trained models so you can develop intuition by reading the output.
Concepts to internalize¶
- Sampling is a loop around the model, not a property of the model. The same
TransformerLMcan produce wildly different output styles depending on the warper settings. Architecture is not destiny. - Logit warpers are pure functions. Same shape in, same shape out, no state. The composition is the strategy; the warpers are the building blocks.
- Mask in logit space, not probability space. Setting dropped logits to
-infis the cleanest way to express zero mass. - The argmax is always kept. Both top-k (for any
k >= 1) and top-p (for anyp > 0) preserve the argmax. A warper that can mask the argmax has a bug. - Temperature reorders nothing. It only changes the sharpness of the distribution. To actually change what the model is most likely to say, you need a different model, not a different temperature.
- The decode loop is
O(T²)without KV cache. Every step recomputes attention over the entire running context. The cost grows quadratically with context length. Later in the course, we'll introduce KV caching to address this. - The diversity-quality tradeoff has no free lunch. Lower temperature → more confident → more repetitive. Higher temperature → more creative → more derailed. Pick a setting per task and don't expect one knob to fit everything.
What we don't cover¶
- Beam search. A breadth-first decode that keeps the top-
kcandidate sequences at every step. Important historically (machine translation), nearly absent from modern LLMs because the diversity-vs-quality tradeoff that beam search optimizes badly maps onto open-ended generation. Skim the Wikipedia entry once. - Typical sampling, mirostat, η-sampling. Variants on top-p with somewhat different cutoff rules. Marginal real-world differences; not worth implementing.
- Logit biasing / forced decoding. Sometimes you want to forbid certain tokens (filtering profanity, requiring JSON), or force certain tokens (constrained decoding, JSON-mode). Both are simple extensions of the warper interface.
What you'll build¶
Package: g2c/sampling/
def apply_temperature(
logits: Tensor,
temperature: float,
) -> Tensor: # SCAFFOLDED
def top_k_filter(
logits: Tensor,
k: int,
) -> Tensor: # SCAFFOLDED
def top_p_filter(
logits: Tensor,
p: float,
) -> Tensor: # SCAFFOLDED
def apply_repetition_penalty(
logits: Tensor,
token_ids: Tensor,
penalty: float,
) -> Tensor: # SCAFFOLDED
@torch.no_grad()
def generate(
model,
prompt_ids: Tensor,
max_new_tokens: int,
...
) -> Tensor: # SCAFFOLDED
Total scaffolded code: roughly 30 lines across five functions. The math is light; the lesson is the order, the masking convention (-inf), and the composition.
How to run the tests¶
Tests live in tests/test_sampling.py. Initial state: 1 passed, 47 failed.
source .venv/bin/activate
pytest tests/test_sampling.py # all module-11 tests
pytest tests/test_sampling.py -x # stop at first failure
pytest tests/test_sampling.py -k temperature # just temperature tests
pytest tests/test_sampling.py -k top_k # just top-k tests
pytest tests/test_sampling.py -k top_p # just top-p tests
pytest tests/test_sampling.py -k repetition # just repetition-penalty tests
pytest tests/test_sampling.py -k generate # just generate tests
pytest tests/test_sampling.py -v # verbose
Exercises¶
To launch the exercise notebook run:
If at any point you want to archive the work in your current notebook and restart fresh:
The notebook auto-loads the strongest available model artifact unless you override it.
- Temperature sweep. Sample the same prompt at several temperatures.
- Top-k vs top-p. Compare truncation strategies at fixed temperature.
- Looping and repetition. Quantify repetition with type-token ratio.
- Interactive playground. Build a small loop for prompt and sampler experiments.
- Greedy two ways. Verify greedy decoding is
temperature=0behavior. - Logit biasing. Forbid selected token IDs and observe the effect.
- Forced first token. Force an opening token and watch the continuation steer.
- Held-out completion comparison. Compare sampled completions against actual held-out text.
Pitfalls to expect¶
-
Masking with
-1e9instead of-inf. Most of the time it works, but when it doesn't, it's hard to fix. -
Top-p off-by-one. A common bug writes the rule as "drop everything once cumulative > p", but breaks on a high-confidence argmax.
-
Warping in probability space instead of logit space. A rewrite that softmaxes early and then tries to apply warpers to probabilities will produce something resembling the right answer but with subtle scale differences and tricky renormalization.
-
Wrong warper order. The canonical order is
repetition_penalty → temperature → top_k → top_p → softmax. Switching the order can produce subtly wrong outputs. -
Repetition penalty applied to the whole prompt. The penalty reads
full_ids, which defaults toprompt + sampled_so_far. If your model refuses to repeat anything in the prompt, consider a separate "recent-only" history. -
Forgetting to crop to
max_seq_len. Generate must pass at mostmax_seq_lentokens to the model, which meansctx = full_ids[-model.max_seq_len:]every step. -
Slicing
logits[:, -1, :]after warping. Warping the full(B, T, V)tensor and then slicing produces the same answer but doesT-fold more work per step. Slice first. -
Forgetting
@torch.no_grad(). Generation builds an autograd graph it never uses. The decorator is provided in the scaffold — don't remove it. -
Re-seeding the generator inside the loop. Seed exactly once, outside the loop.
M-series notes¶
Inference requires relatively minimal compute next to training. Since the notebook uses the largest model you trained in Module 10, your machine will have no problem handling inference on it. Expect anywhere from a few seconds to one minute per sequence, depending on length and model size. We still strongly recommend using MPS over CPU regardless.
Reading¶
Primary:
- Holtzman et al., "The Curious Case of Neural Text Degeneration" (2020). The top-p / nucleus-sampling paper. The figures comparing greedy / pure-random / top-k / top-p output are still the clearest argument for adaptive cutoffs. Read once start to finish.
- Fan, Lewis, Dauphin, "Hierarchical Neural Story Generation" (2018). The top-k paper, in the context of story generation. Older but worth reading; introduces the diversity-vs-quality framing that this whole module is about.
- Keskar et al., "CTRL: A Conditional Transformer Language Model for Controllable Generation" (2019). §4.1 has the repetition-penalty formula we use.
Secondary:
- Karpathy, nanoGPT (GitHub,
model.py::generate). 30 lines of reference Python; the loop is structurally identical to ours, with AdamW-trained weights and no top-p. Reading it after writing your own is illuminating. - HuggingFace
transformersgeneration/logits_process.py. The reference implementation that essentially everyone copies. Has every warper variant in one place; the canonical order (LogitsProcessorList) is what we follow. - Su, Cao, Lin, "A Contrastive Framework for Neural Text Generation" (2022, contrastive search). A more recent decoding method that interpolates between argmax and a degeneration penalty. Argued to outperform top-p in some setups; not widely adopted yet but worth knowing about.
Optional:
- Meister, Pimentel, Wiher, Cotterell, "On Decoding Strategies for Neural Text Generation" (2022). A thorough empirical comparison of every popular decoding method. Useful if you want a survey before going deeper.
- The "typical sampling" paper (Meister et al., 2023). A variant on top-p with somewhat different theoretical motivation. Marginal practical differences; included for completeness.
Deliverable checklist¶
- All tests in
tests/test_sampling.pypass. - Notebook:
notebooks/solutions/11-sampling.ipynb. Load the strongest available model artifact and run exercise 1 (temperature sweep), exercise 2 (top-k vs top-p comparison), and exercise 3 (type-token ratio under varying penalty). Commit the notebook with outputs visible. - Interactive playground from exercise 4 embedded in the notebook, or expanded into a small
scripts/CLI if you want a terminal version. - You can explain — out loud, without notes — the diversity-vs-quality tradeoff and where each warper sits along that axis.
- You can explain — out loud, without notes — why the argmax always survives both top-k and top-p, and what bug each pattern catches.
- You can explain — out loud, without notes — the eight-step decode loop, with cropping, and what breaks if you reorder it.