Module 06 — Next-token prediction¶
Question this module answers: What is the actual training objective of a language model?
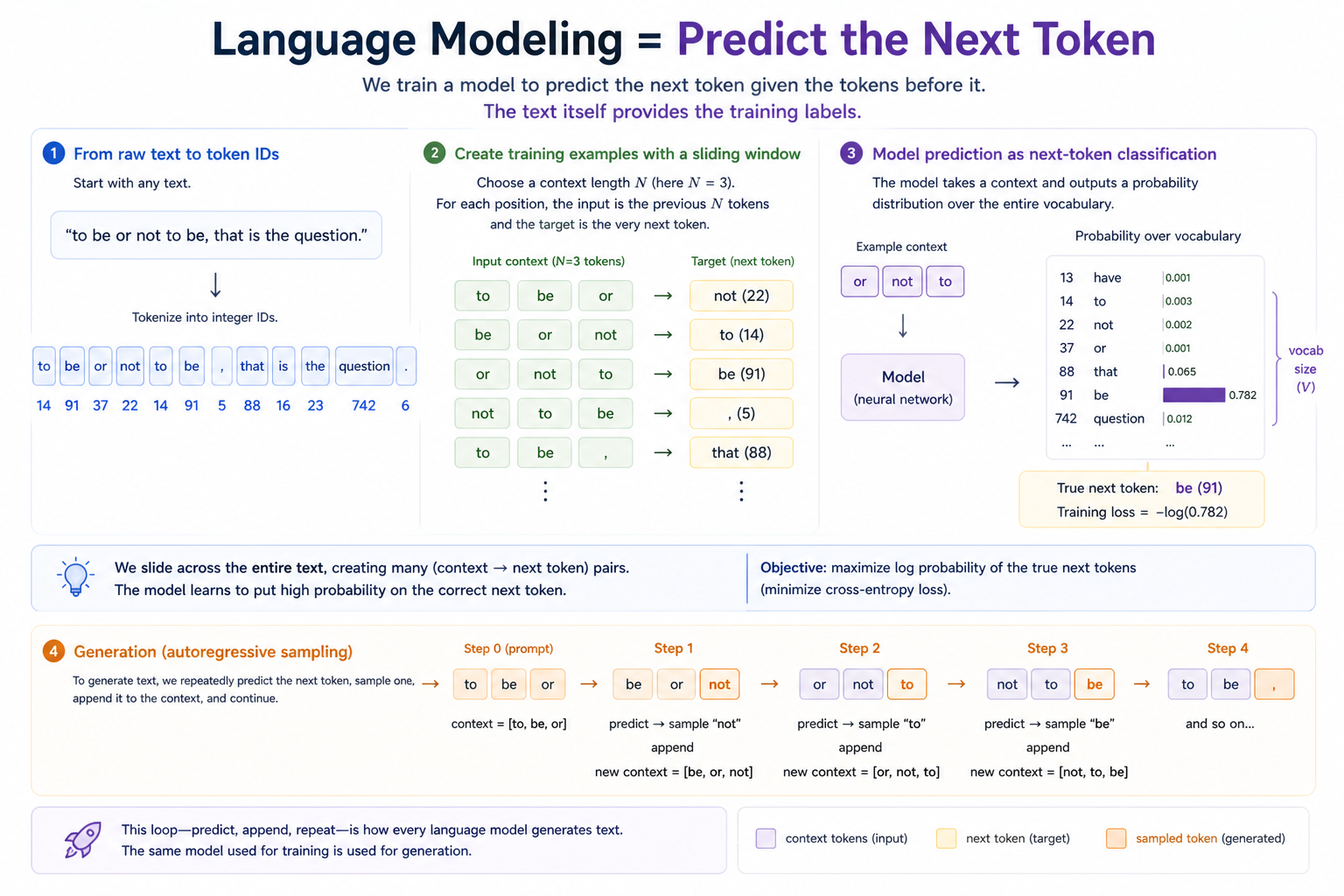
The training-time path and the inference-time path use the same model with the same forward pass — the only difference is whether the next token comes from the corpus (training) or from sampling the model's own output (generation). Internalizing that they're the same loop is what this lesson is built around.
Before you start¶
- Review 03-nn for neural models, 05-embeddings and 04-tokenizer for representing language
- Review PyTorch Primer if any PyTorch code feels unfamiliar or confusing
- Finish the
g2c/nnpackage from 03-nn and theg2c/embeddingspackage from 05-embeddings — this module relies on both
Where this fits in¶
Modules 04 and 05 gave us the input pipeline — text becomes integer IDs becomes vectors. Module 03 gave us a way to train an MLP on labeled data. What we don't yet have is a way to train on text.
The breakthrough is to recast "model the language" as "predict the next token." Given the text so far, what comes next? That's a classification problem with vocab_size classes. Every method we built in Module 03 (cross-entropy loss, SGD, Linear, ReLU) drops in directly. The only differences are:
- The label is just the next token in the corpus. We don't need human-labeled data — we just slide a window forward, and the next token is the target. This is "self-supervision," and it's why LLMs can be trained on the entire internet.
- Inference is autoregressive. To generate text, we predict the next token, append it to the context, predict again, and so on. The generation process IS the prediction process, called repeatedly.
The big idea¶
Next-token prediction is just classification. Take any string, tokenize it. Slide a window of length N (the context length) across the resulting ID sequence. For each window, the input is the window itself and the target is the very next token:
Token IDs: [4, 7, 1, 3, 9, 2, 6, ...]
context_length = 2:
window [4, 7] → target 1
window [7, 1] → target 3
window [1, 3] → target 9
window [3, 9] → target 2
...
Now the problem looks identical to MNIST: the model gets a fixed-size input (a context window) and produces a probability distribution over vocab_size classes (the next token). Cross-entropy loss. SGD. The whole Module 03 setup, unchanged.
The only conceptual addition is what to do at inference time. There's no "true next token" to compare against — we want the model to generate. So we run the model on the prompt, sample one token from the output distribution, append it, run again on the new context, sample again, and so on:
Autoregressive sampling (context_length = 2):
prompt = [4, 7]
step 1: model([4, 7]) → distribution over V tokens; sample → 1
now have [4, 7, 1]
step 2: model([7, 1]) → ... sample → 3
now have [4, 7, 1, 3]
step 3: model([1, 3]) → ... sample → 9
...
That loop IS the inference path of every LLM you've ever talked to. Everything else — top-k sampling, beam search, temperature controls, RAG, tools — is decoration around this exact loop.
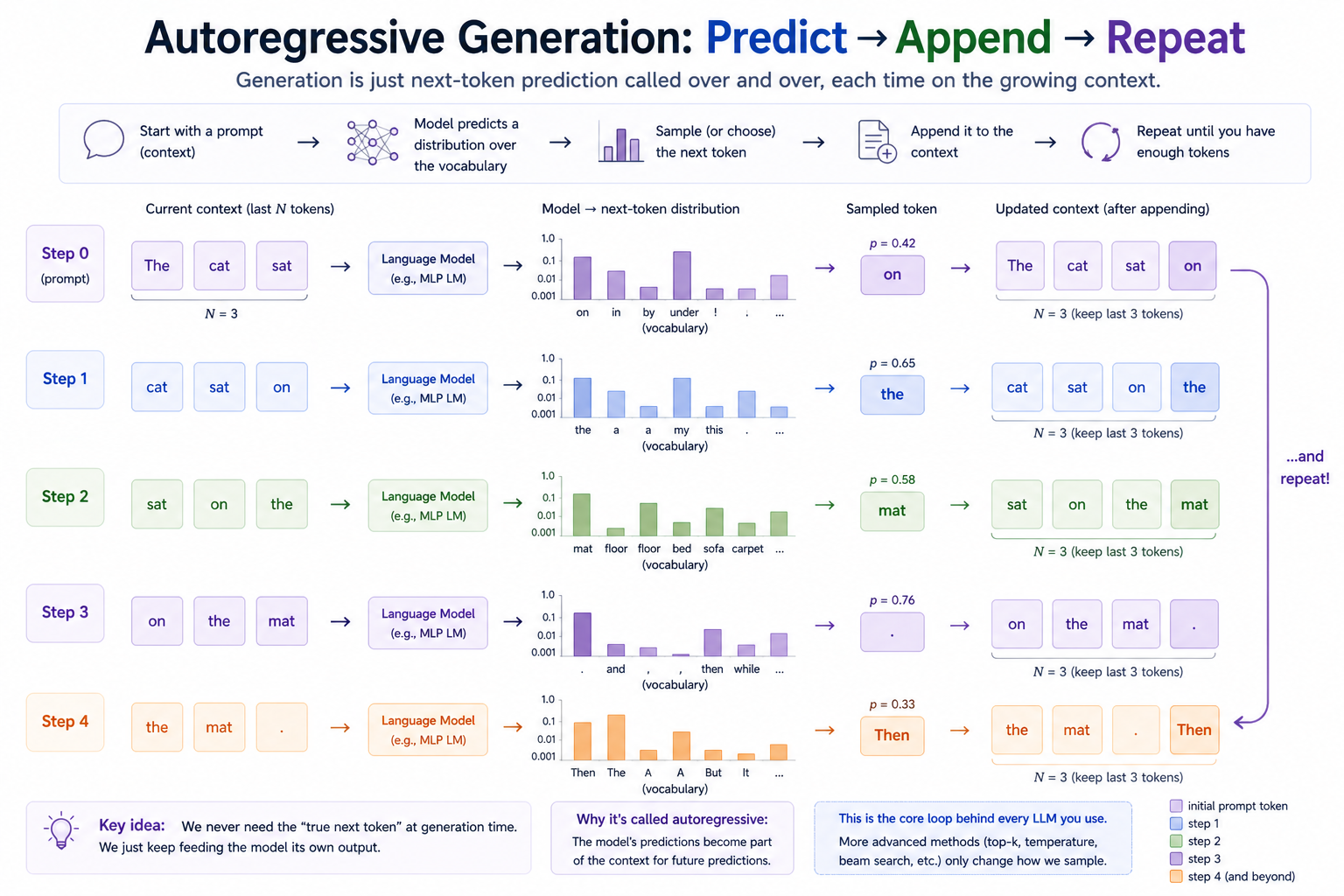 Each step asks the model for a next-token distribution given the current context, samples one token, appends it, and slides the context window forward. It's the same model used during training, just called repeatedly with its own outputs as input.
Each step asks the model for a next-token distribution given the current context, samples one token, appends it, and slides the context window forward. It's the same model used during training, just called repeatedly with its own outputs as input.
The language model ladder¶
This module's deliverable is three language models, increasing in sophistication, all sharing the same training objective:
Architecture Context Parameters
─────────────────────────────────────────────────────────────────────────
CountsBigramLM pure counts table 1 token 0 (counts only)
NeuralBigramLM embed → linear → logits 1 token V·D + D·V + V
MLPLanguageModel embed → concat → MLP → logits N tokens V·D + N·D·H + H·V + ...
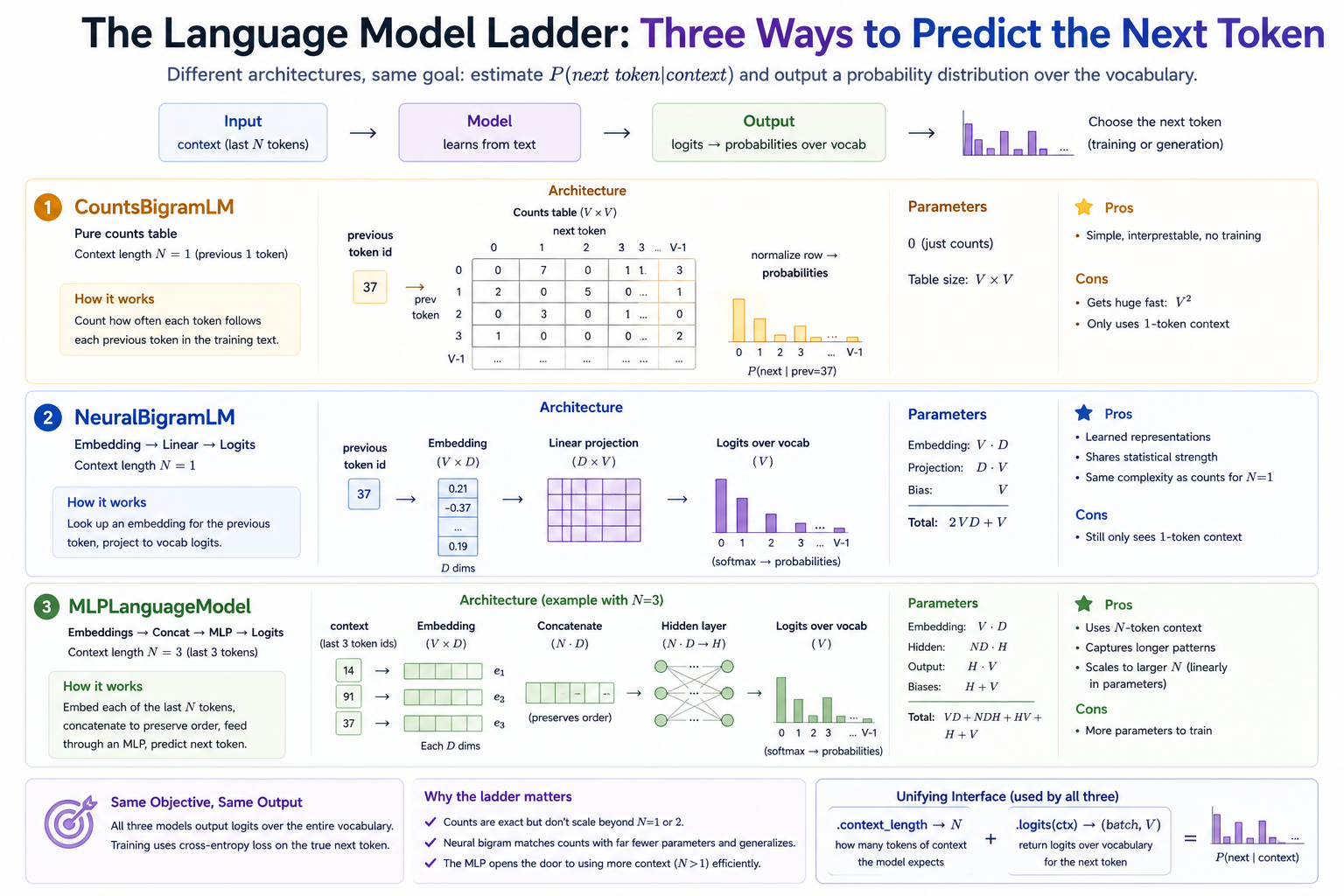 Same input (context tokens), same output (a probability distribution over the vocabulary), three increasingly expressive ways to compute it.
Same input (context tokens), same output (a probability distribution over the vocabulary), three increasingly expressive ways to compute it.
Counts vs. neural: same model, two implementations¶
For a bigram model — context length 1, predicting P(next | prev) — there are two ways to learn the conditional distribution.
Counts. Walk the corpus once. For each adjacent pair (a, b), increment counts[a, b]. Done. The conditional distribution at inference is row a of the table, normalized to sum to 1. With vocab_size = V, this is a (V, V) table — for a small vocab this is genuinely the right tool. No hyperparameters, no training, no neural network at all.
Bigram counts table after a tiny corpus:
next token
0 1 2 3
prev 0 [ 0 7 0 1 ]
1 [ 2 0 5 0 ]
2 [ 0 3 0 1 ]
3 [ 1 0 0 0 ]
Row 0 normalized: [0.000, 0.875, 0.000, 0.125]
→ P(next=1 | prev=0) = 0.875
Neural. Same target distribution, parameterized as softmax(embed(a) · W) where embed is a (V, D) lookup table and W is a (D, V) projection. Train with cross-entropy and SGD. With sufficient D this can match the counts model exactly. With smaller D it can't quite — but it learns to share statistical strength across similar tokens, which the counts model fundamentally cannot do.
Both perform similarly on a simple corpus. The point of building both is to internalize that the neural one is the same model — just expressed in a form that scales to larger contexts and stacks of layers, which the counts table does not. Counts hits a wall at context_length = 2 (table size V³); at context_length = 3 it's V⁴; by realistic context lengths the table doesn't fit anywhere. The neural form's parameter count grows linearly in D and H, not exponentially in N.
From bigram to MLP: more context¶
A bigram model only sees the previous token. That ceiling is real and quickly hit. The fix is the Bengio-style MLP language model (Bengio et al. 2003):
Context window: [a, b] (context_length = 2)
a ─→ embed ─→ e_a (D dims)
┐
│── concat ─→ [e_a, e_b] (2·D dims)
b ─→ embed ─→ e_b (D dims)
│
↓
hidden Linear (2·D → H)
│
↓
tanh
│
↓
output Linear (H → V)
│
↓
logits over V tokens
That's it. A trigram model (context_length = 2, predicting the third token from the previous two) is just this with N = 2. A four-gram is N = 3. There's no upper limit other than parameter count.
Why concatenation, not summing or averaging? Concatenation preserves position. After concat, [e_a, e_b] and [e_b, e_a] are different vectors; after summing, they're the same. The model that sums embeddings of context tokens cannot tell dog bites from bites dog — exactly the bag-of-tokens failure mode that motivated positional embeddings in Module 05. The MLP's concatenation is a brute-force-but-correct way to inject position; in Module 09 the transformer block uses a more elegant scheme.
The Bengio architecture is the direct ancestor of the transformer. Most of what makes transformers work is replacing the fixed-size context window and its concatenated embeddings with a variable-size context window and attention-mixed embeddings. The next-token-prediction objective, the cross-entropy loss, the embedding table, the output projection — those all stay.
Perplexity: how surprised is the model¶
The headline metric for any LM. Perplexity is exp(mean cross-entropy per token) on a held-out corpus. Intuitively:
The model behaves, on average, as uncertain as if it were uniformly choosing from
perplexitytokens.
Sanity values for a vocab of size V:
Uniform model (all tokens equally likely): perplexity = V
Perfect model (always puts mass 1 on the right token): perplexity = 1
Bigram on English (~50k vocab): ~100s
Small neural LM: ~tens
Modern frontier LMs: single digits
Two reasons to use perplexity over raw cross-entropy:
- It's interpretable as a branching factor. "Perplexity 50" tells you the model is acting as if it's picking from a uniform distribution over 50 tokens. Cross-entropy in nats doesn't have that interpretation directly.
- It's invariant to vocab encoding choices. A model trained at vocab size 1k vs 8k has very different cross-entropy values, but their perplexities are still comparable as long as you evaluate on the same token stream.
When you train a neural LM, you watch train loss (training cross-entropy) go down step-by-step and val perplexity (held-out perplexity) go down checkpoint-by-checkpoint. They tell the same story in different units.
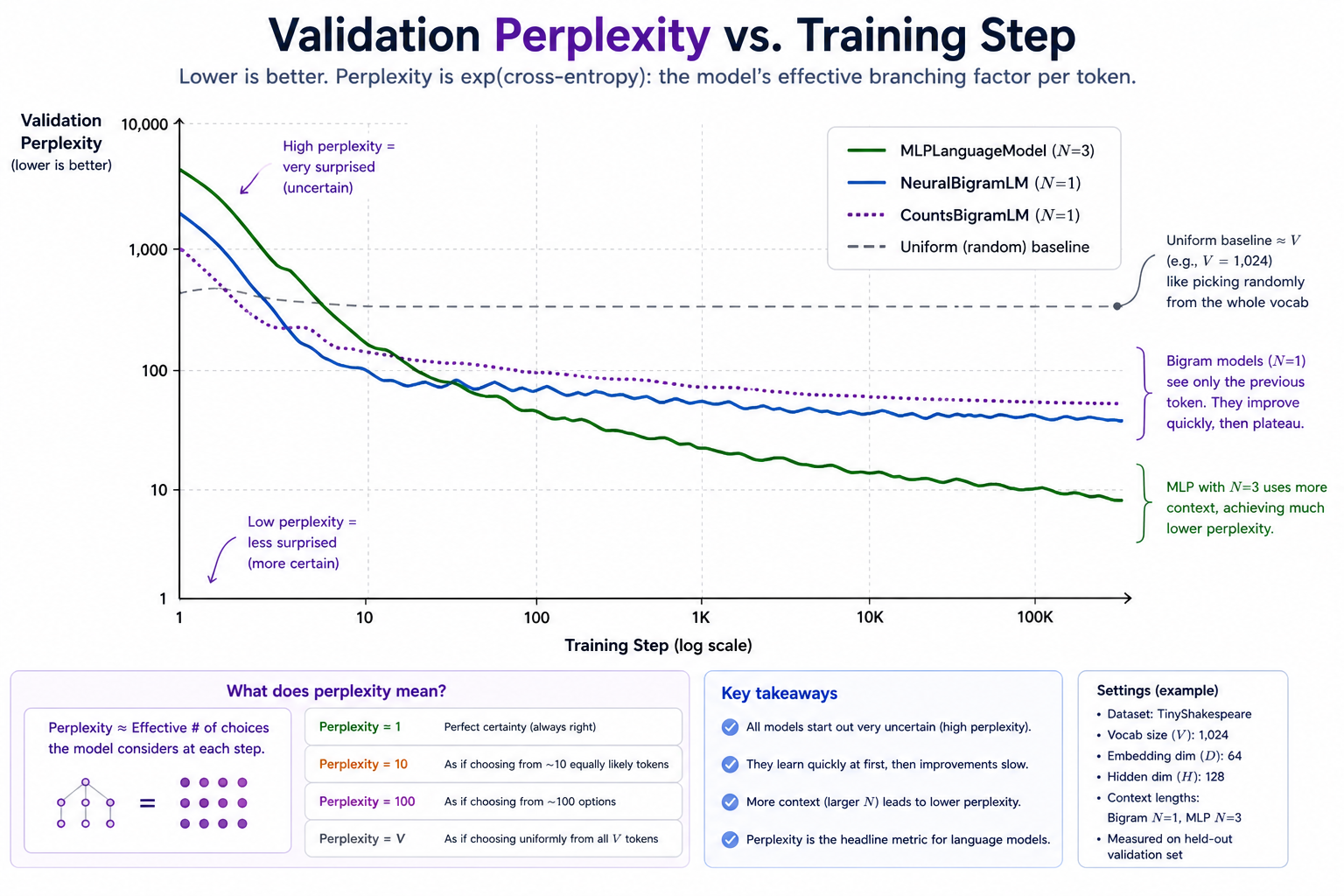 The uniform baseline at perplexity = vocab_size is where any untrained model starts. The counts bigram and neural bigram converge to roughly the same floor (same model, two parameterizations). The MLP, with N-token context, drops past that floor — that gap is exactly what extra context buys you.
The uniform baseline at perplexity = vocab_size is where any untrained model starts. The counts bigram and neural bigram converge to roughly the same floor (same model, two parameterizations). The MLP, with N-token context, drops past that floor — that gap is exactly what extra context buys you.
Concepts to internalize¶
- Self-supervision is the trick. The "label" is just the next token in the corpus. No human labelers needed. This is what unlocks training on internet-scale text and is the single most important practical idea behind modern LMs.
- Inference is autoregressive. Generation = repeated next-token prediction with the previous output appended to context. The same model architecture serves both roles — there's no separate "generator."
- Counts and neural bigrams represent the same distribution. The choice is parameterization, not capacity. Neural is preferred not because it fits better on small vocab, but because it scales — to more context, to deeper stacks, to shared parameters across similar tokens.
- Concatenation preserves position. Inside the MLP language model, flattening the context-window embeddings is what tells the model whether token
acame before or after tokenb. Sum or average would lose this. - Perplexity is
exp(cross-entropy). Same number, different units. Perplexity is the more interpretable one: it's the effective branching factor at each step.
What you'll build¶
Package: g2c/lm/
class CountsBigramLM:
counts: torch.Tensor # (V, V) integer table
smoothing: float # add-one Laplace smoothing
context_length: int = 1
def fit(self, ids: torch.Tensor) -> None: ...
def logits(self, ctx_ids) -> torch.Tensor: ...
class NeuralBigramLM(Module):
embed: TokenEmbedding # (V, D)
proj: Linear # (D, V)
context_length: int = 1
def forward(self, ctx_ids) -> torch.Tensor: ...
class MLPLanguageModel(Module):
embed: TokenEmbedding # (V, D)
hidden: Linear # (N·D, H)
output: Linear # (H, V)
context_length: int # = N
def forward(self, ctx_ids) -> torch.Tensor: ...
# Helpers in train.py — model-agnostic, use only `.context_length` and `.logits()`
def get_batch(ids, context_length, batch_size): ... # implemented
def perplexity(model, ids, *, batch_size=256, device="auto") -> float: ...
def sample(model, prompt_ids, num_tokens, *, temperature=1.0, device="auto") -> torch.Tensor: ...
def train_lm(model, train_ids, *, val_ids=None, device="auto", ...) -> dict: ...
Roughly 50 lines of code split between each implementation. They all share the same interface and are generally interchangeable in the exercises.
How to run the tests¶
Tests live in tests/test_lm.py. Initial state: 13 passed, 35 failed.
source .venv/bin/activate
pytest tests/test_lm.py # run all module-06 tests
pytest tests/test_lm.py -x # stop at first failure (recommended)
pytest tests/test_lm.py -k counts # only the counts-model tests
pytest tests/test_lm.py -k mlp # only the MLP tests
pytest tests/test_lm.py -v # verbose
Exercises¶
To launch the exercise notebook run:
If at any point you want to archive the work in your current notebook and restart fresh:
The notebook starts with a test gate, then walks through prediction, training, sampling, and comparison.
- Context windows and targets. Turn a token stream into supervised next-token examples.
- Counts bigram model. Inspect counts, smoothing, and next-token probabilities.
- Neural bigram and MLP shapes. Verify logits and context-order behavior.
- Perplexity and sampling. Connect cross-entropy to predict-append-repeat generation.
- Train all three models. Compare counts, neural bigram, and MLP validation perplexity. If the reusable
ShakespeareTokenizerartifact exists, the notebook uses its full 4096-token vocabulary; otherwise it trains a smaller local tokenizer as a fallback. - Read generated text. Compare failure modes qualitatively.
- Plot training curves. Use the counts model as a baseline for neural training curves.
Pitfalls to expect¶
-
fitnot accumulating. Callingfittwice should add to the existing table, not replace it. Reset the counts in__init__, not infit. -
Smoothing zero by accident. Without smoothing (or with
smoothing=0), any unseen bigram pair has probability zero, which makeslog(0) = -inf, which propagates through perplexity asinf. The defaultsmoothing=1.0fixes this; if a user explicitly setssmoothing=0, expect-infin log-probs and accept it. -
Forgetting to squeeze a
(batch, 1)context.NeuralBigramLM.forwardreceives(batch, 1)inputs fromget_batch(becausecontext_length=1produces a length-1 context window). Without a squeeze,embedreturns(batch, 1, D)and the projected logits are(batch, 1, V), breaking every downstream shape assumption. -
MLP using sum/mean instead of concat. The MLP's flatten step is
e.view(B, -1), which preserves order.e.mean(dim=1)would silently collapse[a, b]and[b, a]to the same vector. -
train_lmnot zeroing grads. Standard PyTorch trap. Withoutoptimizer.zero_grad()between steps, gradients accumulate across iterations and SGD walks in roughly random directions. The training-loss curve will look haywire. -
Sampling without
torch.no_grad(). Not a correctness bug — but every sampling step builds an autograd graph that's never used, wasting memory and time. Wrap thesampleloop body inwith torch.no_grad():for free speedup. Same goes for the inner loop ofperplexity. -
Perplexity blowing up on a tiny held-out set. If
val_idsis shorter thancontext_length, perplexity is undefined (no windows to score). The test for this throwsValueErrorfromget_batch; forperplexityitself, guaranteelen(val_ids) > context_lengthin the calling code. -
Comparing perplexities across vocab sizes. A bigger vocab makes every individual prediction harder; perplexities aren't directly comparable across tokenizers. For exercise 5, train all three models on the same tokenized stream so the comparison is fair. If your notebook uses the fallback tokenizer, compare those runs only to other fallback-tokenizer runs.
M-series notes¶
This module is light on compute.
- The counts table for
vocab_size = 4096is about 128MB; atvocab_size = 8192it is about 512MB for the integer counts table before any temporary tensors. Fine on a 16GB machine at the notebook sizes, but getting heavy. This is a glimpse of why counts models don't scale. - The neural bigram and MLP at the sizes used in exercise 5 have well under 1M parameters. CPU is fine, but MPS starts to pay off when you push steps, hidden size, or vocab size upward.
train_lm(..., device="auto")moves trainable neural models and sampled minibatches to MPS when available. CountsBigramLM stays CPU-side because it is a plain counts table.
Reading¶
Primary:
- Karpathy, "Building makemore" — the YouTube series. Parts 1–3 cover exactly the three models in this module: counts bigram, neural bigram, and the Bengio MLP. Single best resource on the topic.
- Bengio et al., "A Neural Probabilistic Language Model" (2003). The paper that introduced the architecture you're building in
mlp.py. A surprisingly short read; the conceptual machinery is small. The "look up embeddings, concatenate, MLP, softmax" recipe is right there.
Secondary:
- Jurafsky & Martin, Speech and Language Processing (3rd ed.), ch. 3. Classical-NLP treatment of n-gram language models, smoothing, and perplexity. Free PDF online. Read the perplexity section if you want a deeper account of why this is the canonical metric.
- Mikolov et al. (2010), "Recurrent Neural Network Language Model." The first big jump past Bengio's MLP. We don't implement RNNs in this course (we go straight to attention), but the paper is a useful waypoint for understanding what attention later replaces.
Deliverable checklist¶
- All tests in
tests/test_lm.pypass. -
notebooks/solutions/06-language-models.ipynb: counts, neural bigram, MLP all trained and evaluated on the same token stream; perplexity comparison table; sampled text from each. -
notebooks/solutions/06-language-models.ipynb: training-loss and validation-perplexity plots for the neural bigram and the MLP. - You can explain — out loud, without notes — why a counts model can represent the same distribution as a neural bigram, but does not scale to context length 3 the way the MLP does.