Module 13 — Instruction tuning (SFT)¶
Question this module answers: How do we make the model follow requests?
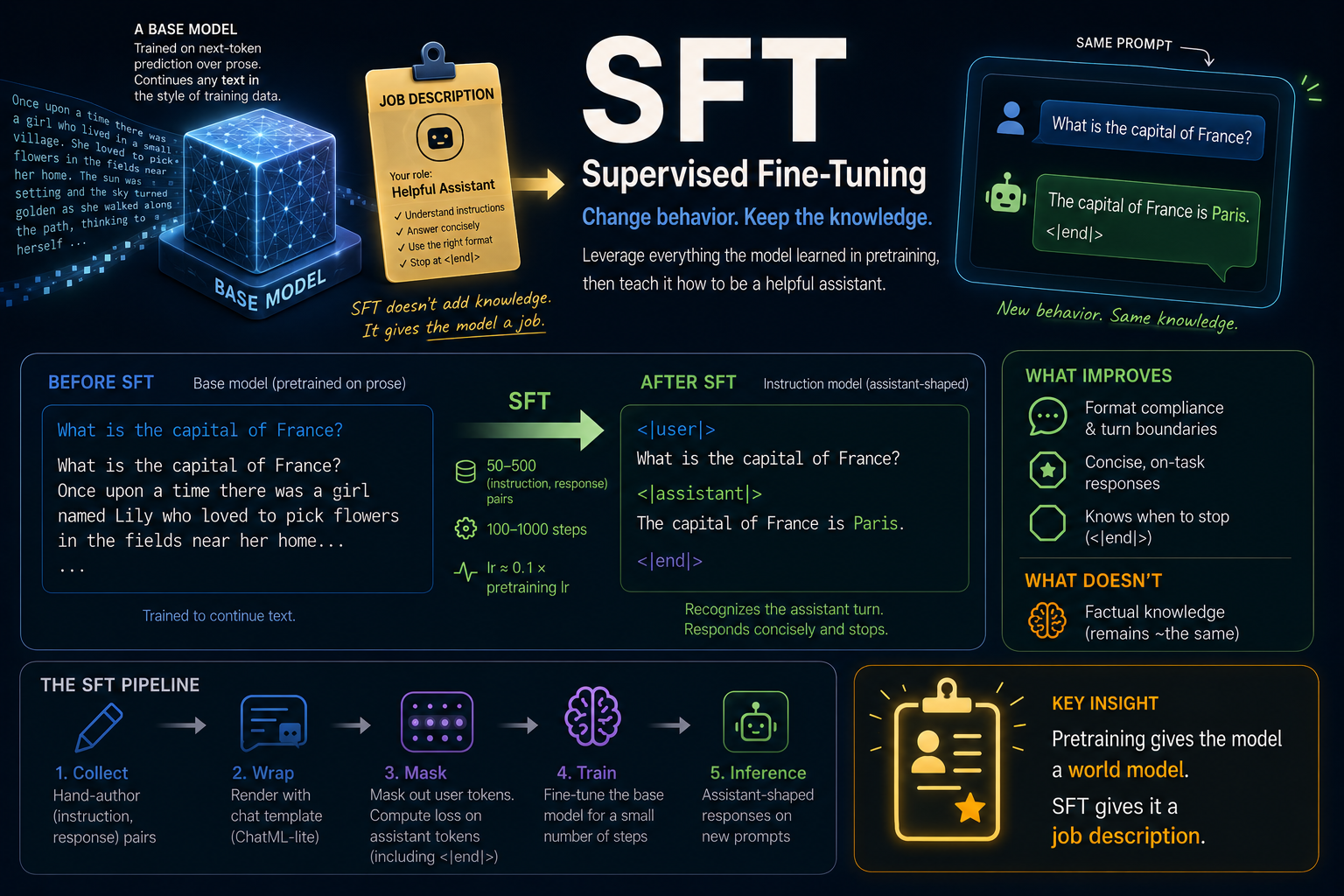
This week is about how to shape model behavior. The mechanics are minimal but the qualitative effect is the largest single change in this course. The model goes from "autocompletes prose" to "answers questions like an assistant." The entire data set is 50 directed examples. Everything else is plumbing.
Before you start¶
- Review
- 10-tinyllm for the training-loop contract
- PyTorch Primer if any PyTorch code is unfamiliar or confusing
- Finish
g2c/nnfrom 03-nng2c/trainingfrom 03b-trainingg2c/tokenizerfrom 04-tokenizer- Either
./baselm.shfor the default BaseLM path, or at least one trained model from 10-tinyllm (ShakespeareLM,StoryLM, orTinyLLM) if you want the course-artifact path - Trained tokenizer from 04-tokenizer (alternatively run
./datasets.sh)
- Run
./baselm.shto setup the model we'll use for post-training
Where this fits in¶
After Module 10 you should have at least one model that's completed pretraining. This is a base model — its training objective was "predict the next token in corpus-style prose." If you give it the prompt:
…the 5M StoryLM model produces something like:
What is the capital of France?
Once upon a time there was a girl nemed Lily who loved to pick flowers...
It doesn't matter how big you make it — at any size, a base model trained on prose continues prose. This is correct behavior under the training objective. The model isn't broken. It's just not an assistant.
The exercise notebook defaults to BaseLM because it has enough broad pretraining for the behavioral shift to be obvious. You can switch the model-selection cell to MODEL_SELECTION = "course" to run the same SFT loop on your own StoryLM or TinyLLM artifact. If you have a capable self-trained artifact (30M or larger), MODEL_SELECTION = "auto" prefers your own model and falls back to BaseLM when there isn't one. A 1M-class model is generally too weak for the shift to be legible.
The big idea¶
If we want to "answer questions in a structured format" rather than "autocomplete text", we don't have to train a new model entirely from scratch. Rather, we can leverage all the learning and data already in the pretrained model by making small but directed post-training updates.
Supervised fine-tuning (SFT) is the first layer of post training in a modern LLM stack. It is primarily used to make the raw model useful by teaching it to respond in assistant format and style. The recipe:
- Collect or hand-author a few hundred
(instruction, response)pairs. - Wrap each pair in a chat template — a literal-text format with role markers.
- Apply a mask that says "compute loss on the assistant tokens, not the user tokens."
- Train the base model on these examples for a small number of steps.
That's the whole pipeline. There is no new architecture, no new optimizer, no new loss class — just the same TransformerLM and the same Trainer you've already built, with a different data source and a masked variant of cross-entropy.
An SFT'd model stops continuing text and starts producing assistant turns. Often short, often plausible-sounding, often wrong on facts (that's a Module 15 problem). The model has not learned new facts. It has learned a new format.
 SFT is about shaping assistant-shaped text, not teaching new abilities.
SFT is about shaping assistant-shaped text, not teaching new abilities.
The "knowledge stays the same" claim is empirically robust: SFT'd models, probed for factual recall, score within a few percent of their base versions on factual benchmarks. What changes dramatically is response style — short vs long, format-compliant vs free-form, refusal-aware vs refusal-naive.
Chat templates as a learned format¶
A chat template is a deterministic encoder from a list of role-tagged messages. The template contains role markers — short fixed sequences that delimit turns — and the model learns to recognize and emit them.
We'll use a ChatML-lite template — the spirit of ChatML, but with the course-native special tokens reserved.
Unlike a plain BPE string, each marker here is atomic: <|user|>, <|assistant|>, and <|end|> each encode to one reserved token ID. (The tokenizers used by this course have pre-reserved ChatML-like special tokens.)
Every downstream system must use the same chat template: same role tokens, same <|end|> convention, and same newline layout. If inference uses even slightly different markers, the model sees an unfamiliar prompt shape and regresses.
┌────────────────────────────────────────────────────────────────┐
│ ChatML-lite template, special-token aware │
├────────────────────────────────────────────────────────────────┤
│ │
│ <|user|>\n │
│ {content}\n │
│ <|assistant|>\n │
│ {content}<|end|> │
│ │
│ - Newline after the role marker. │
│ - Newline AFTER user content (separator to next role). │
│ - NO newline after assistant content — <|end|> is glued. │
│ - <|end|> ONLY closes the assistant turn. │
│ User turns end at the trailing \n. │
│ │
└────────────────────────────────────────────────────────────────┘
The termination asymmetry is intentional. At inference time the model emits assistant text, and we need a single distinctive stop token. But the user's turn text comes from outside the model, so it doesn't need a special end marker.
Why does the model learn this? Because every SFT example trains it to associate the prefix <|assistant|>\n with "now produce concise content followed by <|end|>." The marker tokens are arbitrary. What matters is that they appear consistently in the same positions across every training example. After ~100 examples the model will essentially memorize this format.
Data quality versus data quantity¶
The headline from the LIMA paper: Less Is More for Alignment. They showed that 1000 carefully-curated SFT examples produces a chat model nearly indistinguishable from tens of thousands of crowd-sourced examples. The active ingredient is consistency: every example follows the same format, every assistant response is well-structured, and the dataset lacks the noise floor that comes from crowd labelers.
At toy scale this is even more pronounced. With 50 hand-authored examples:
- If 48 are clean and 2 are off-pattern (e.g. assistant says "Sure, let me…" while the rest are direct), the model occasionally apes the off-pattern phrasing.
- If 30 are factual Q&A and 20 are creative writing, the model behaves bimodally — switching styles based on subtle cues — and is worse at both than a model trained on either alone.
- If every example ends with exactly one sentence, the model learns exactly one sentence as the assistant turn, regardless of the question.
At small scale, the model overfits to your dataset's surface regularities. This is both a feature and a bug. The exercises ask you to author the dataset yourself because the experience of writing 50 consistent examples is the fastest way to internalize what "consistency" means.
SFT Training¶
SFT uses the same basic gradient descent loop we used for pretraining. The difference is the data. Instead of training on raw text, we train on curated examples of desired behavior.
Compared to pretraining, SFT requires orders of magnitude less data because we aren't trying to teach language from scratch. We are mostly teaching how to respond: the assistant format, the tone, the structure of answers, and the behavior we want after a user instruction.
The hyperparameters below are not universal rules. They are practical starting points for small models. As always, try sweeping at different settings and compare results.
- 50–500 examples. Quality matters much more than quantity. Counterintuitively, larger models need fewer examples (but higher quality) since they tend to have more abilities.
- 100–1,000 optimizer steps. The main danger is overfitting from the model memorizing a tiny dataset. Watch samples and validation loss closely for early stopping.
- Learning rate at 5–20% of pretraining. Larger models are more sensitive to regression from aggressive SFT, and should start lower. This is a fraction of the base model's own pretraining lr, so the right absolute value moves with your base — and the notebook applies that rule for you rather than hardcoding a number. It reads the base artifact's recorded pretraining lr and takes 10% of it, so a course checkpoint pretrained at
3e-4is fine-tuned at3e-5. BaseLM publishes no pretraining lr, so it falls back to3e-4— which is the SFT learning rate Hugging Face used for SmolLM's own instruct variants. Watch the printed value: if you ever see SFT running at the same lr the base was pretrained at, that is the catastrophic-forgetting recipe below.
┌─────────────────────────────────────────────────────────────────────┐
│ │
│ BASE model (Module 10 checkpoint) │
│ trained on: next-token prediction over prose │
│ behavior: continues any text in the style of training data │
│ knowledge: whatever the corpus contained │
│ │
│ ┌──────────────────┐ │
│ │ SFT │ ── 50–500 (instruction, response) │
│ │ fine-tuning │ pairs │
│ └────────┬─────────┘ ── 100–1000 fine-tuning steps │
│ │ ── lr ≈ 0.1 × pretraining lr │
│ ▼ │
│ │
│ INSTRUCTION model │
│ trained on: pretraining objective + SFT pairs │
│ behavior: answers in turn-shaped format on prompt │
│ knowledge: ALMOST IDENTICAL to base — SFT moves behavior, │
│ not facts │
│ │
└─────────────────────────────────────────────────────────────────────┘
Loss masking¶
In pretraining, every token in the window is a training target. The model learns to predict tokens uniformly across the corpus. In SFT, the model should not learn to predict user tokens. Those tokens come from the user at inference time. Training to predict them would actively damage behavior.
The fix is the loss mask: a (T-1,) boolean tensor that's 0 at every user token and 1 at every assistant token (including the <|end|> token).
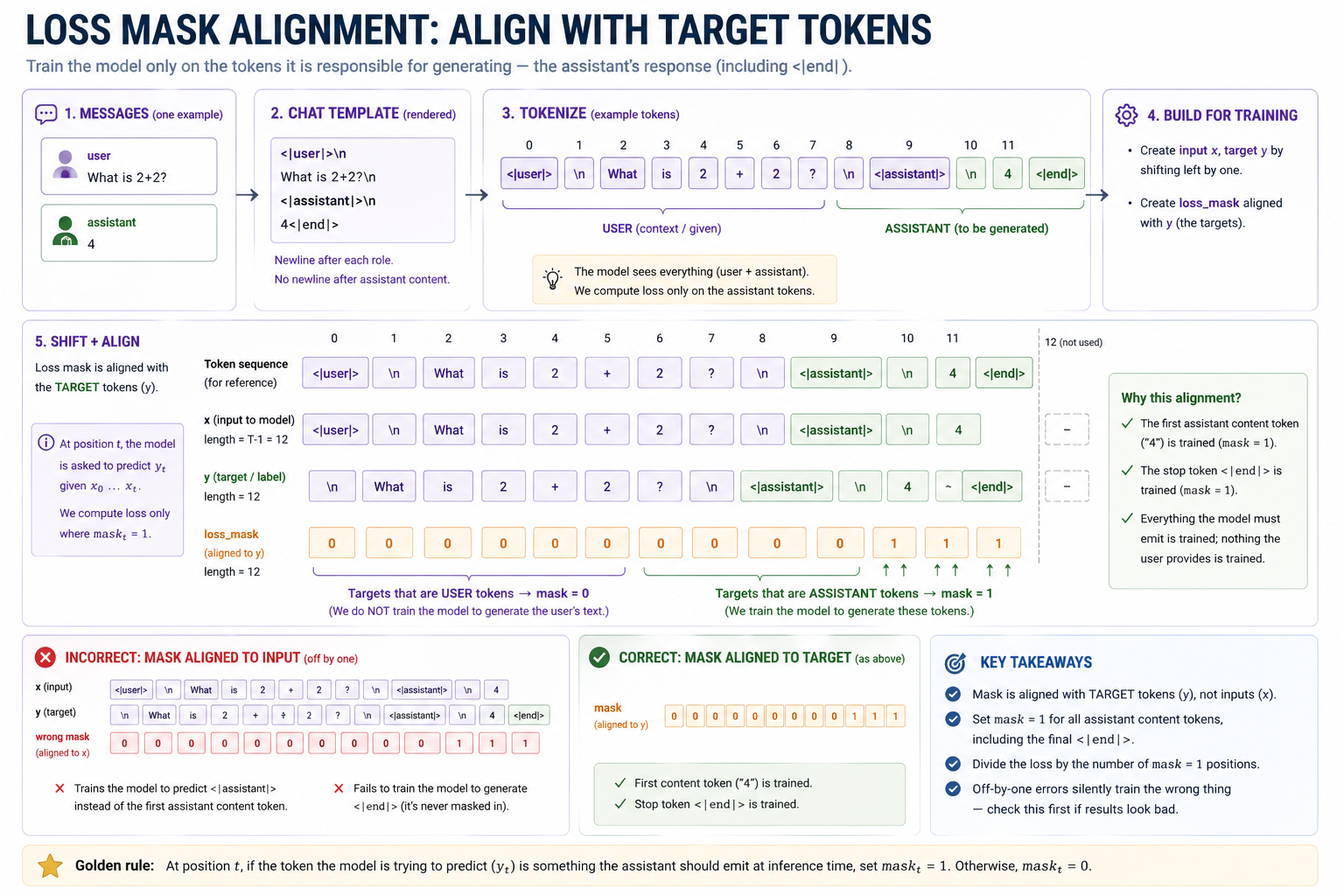 The shift-by-one between
The shift-by-one between mask and y is the bug-prone seam — get it right once and the rest of the SFT pipeline follows.
The masked-loss formula is the same familiar cross-entropy formula, but only applied to 1-masked tokens:
per_pos_loss = CE(logits, y, reduction='none') # (B, T-1)
masked_total = (per_pos_loss * loss_mask).sum() # scalar
masked_count = loss_mask.sum() # scalar
loss = masked_total / masked_count # scalar
Format collapse and other failure modes¶
The visible failure modes of toy-scale SFT, in roughly the order you'll encounter them:
┌────────────────────────────────────────────────────────────────┐
│ FORMAT COLLAPSE │
│ The model produces the right format on every prompt — even │
│ prompts where the format is wrong. Asked to continue a │
│ poem, it answers in a single sentence. Symptom: model is │
│ always assistant-shaped. │
│ Fix: usually nothing — at this scale, format collapse is │
│ inherent. At larger scale, mix in pretraining data. │
└────────────────────────────────────────────────────────────────┘
┌────────────────────────────────────────────────────────────────┐
│ ROLE LEAKAGE │
│ The model emits "<|user|>" mid-response and pretends to be │
│ the user. Symptom: a third turn appears unprompted. │
│ Fix: ensure every training example ends cleanly with │
│ <|end|>; check the loss mask actually covers <|end|>. │
└────────────────────────────────────────────────────────────────┘
┌────────────────────────────────────────────────────────────────┐
│ FORMAT FORGETTING │
│ After SFT, the model cannot complete a prose passage. │
│ "To be, or not to be, ..." gets answered with a definition │
│ instead of continued. Symptom: the base behavior is gone. │
│ Fix: reduce SFT step count, lower lr, mix in pretraining. │
│ At our scale, accept some forgetting. │
└────────────────────────────────────────────────────────────────┘
┌────────────────────────────────────────────────────────────────┐
│ CATASTROPHIC FORGETTING │
│ Model degrades at SFT objective AND base objective. Loss │
│ curve looks fine; outputs are gibberish. Symptom: too many │
│ SFT steps at too high lr. Fix: lower both — halve the lr │
│ and shorten the run before changing anything else. │
└────────────────────────────────────────────────────────────────┘
┌────────────────────────────────────────────────────────────────┐
│ REPETITION / LOOPING │
│ The assistant never emits <|end|> and keeps going. │
│ Symptom: response runs to max_new_tokens. Fix: re-check │
│ the loss mask covers <|end|>; add a few examples with │
│ short responses to teach early stopping; sample with a │
│ small repetition_penalty (Module 11). │
└────────────────────────────────────────────────────────────────┘
┌────────────────────────────────────────────────────────────────┐
│ CONFIDENT HALLUCINATION │
│ The format is perfect; the content is invented. The 30M │
│ model "knows" the capital of France is "Lyon." Symptom: │
│ fluent-sounding wrong answers. Fix: cannot — this is a │
│ capability problem, not a format problem. Module 15 returns │
│ to it as the headline failure mode of toy-scale models. │
└────────────────────────────────────────────────────────────────┘
The first three are training problems — fixable by adjusting data or hyperparameters. The bottom three are deeper. Catastrophic forgetting is fixable by stopping earlier. Repetition is fixable by checking your loss mask. Confident hallucination is not fixable by SFT.
Concepts to internalize¶
- SFT changes behavior, not knowledge. A model that didn't know X before SFT doesn't know X after SFT either. What changed is response style.
- The chat template is part of the model. Every system that calls the SFT'd model must use the same role/end tokens and newline layout the model was trained on. A single typo is enough to revert behavior.
- Loss masking is the critical implementation trick. Without it, the model also learns to predict user text, instead of just assistant text.
- 50–500 examples. Not 5; not 5000. The dataset is small enough to read end-to-end and audit; large enough to teach a stable convention.
- Data quality dominates data quantity. Inconsistent examples teach inconsistent format. Spend the curation effort.
- The model may answer perfectly and still be wrong. Format compliance is not truth. An SFT'd toy model is the best demonstration of this distinction in the course — it answers questions confidently in well-formatted prose, and almost everything it says is invented.
What we don't cover¶
- System prompts. A leading
<|system|>You are a helpful assistant.<|end|>turn is the third role real systems support. We omit it at toy scale. - PEFT prompt tuning, prefix tuning, P-tuning. Pre-LoRA parameter-efficient methods that train a small set of "soft prompt" tokens. Largely superseded by LoRA. Skim once; don't implement.
- Continual / online SFT. Updating the model as new examples arrive. Production concern with its own catastrophic-forgetting issues; out of scope.
What you'll build¶
Package: g2c/sft/
class ChatTemplate:
USER: str = "<|user|>"
ASSISTANT: str = "<|assistant|>"
END: str = "<|end|>"
def render(self, messages: list[dict]) -> str: # SCAFFOLDED
def render_with_mask(
self,
messages: list[dict],
tokenizer,
) -> SFTExample: # SCAFFOLDED
class SFTExample(NamedTuple):
ids: list[int] # implemented
mask: list[int] # implemented
def pad_and_collate(
examples: list[SFTExample],
*,
max_seq_len: int,
pad_id: int,
) -> tuple[Tensor, Tensor, Tensor]: # SCAFFOLDED
def masked_cross_entropy(
logits: Tensor, # (B, T, V)
targets: Tensor, # (B, T)
mask: Tensor, # (B, T) — 1 where loss applies, 0 elsewhere
) -> Tensor: # SCAFFOLDED
class SFTTrainer:
def lr(self, step: int | None = None) -> float: # implemented
def train_step(self) -> dict[str, float]: # SCAFFOLDED
def evaluate(self, eval_examples) -> float: # implemented
def train(self, eval_examples=None) -> dict[str, list]: # implemented
Total scaffolded code: roughly 50 lines across five locations.
How to run the tests¶
Tests live in tests/test_sft.py. Initial state: 10 passed, 34 failed.
source .venv/bin/activate
pytest tests/test_sft.py # all module-13 tests
pytest tests/test_sft.py -x # stop at first failure
pytest tests/test_sft.py -k chat_template # template tests only
pytest tests/test_sft.py -k pad_and_collate # collator tests only
pytest tests/test_sft.py -k masked_cross # loss tests only
pytest tests/test_sft.py -k trainer # trainer tests only
pytest tests/test_sft.py -v # verbose
Exercises¶
To launch the exercise notebook run:
If at any point you want to archive the work in your current notebook and restart fresh:
The notebook carries the exact dataset format, training cells, and comparison prompts.
- Hand-author SFT data. Create a tiny instruction-following dataset.
- Run SFT. Train and compare base vs SFT outputs.
- Loss-mask ablation. Observe what changes when assistant-only masking is removed.
- Format collapse. Probe whether the model learned the chat template.
- Data-size sweep. Compare small, medium, and larger SFT datasets.
- Pretraining loss after SFT. Check how behavior shaping affects base-LM loss.
- Optional LR sweep. See how SFT reacts to learning-rate scale.
- Optional inconsistency injection. Measure how noisy style examples contaminate outputs.
Pitfalls to expect¶
- Loss-mask off-by-one. The mask aligns with next-token targets, not raw input IDs. A one-token shift trains the wrong positions.
- Prompt-format drift. Training and inference must use the same special tokens, newlines, and
<|end|>convention. - Wrong denominator. Average the loss over masked assistant tokens only. Padding and user tokens should not affect the gradient scale.
- Forgetting
<|end|>. If the end marker is not in the supervised span, the model will not learn when to stop. - Learning rate or step count too high. SFT can damage base behavior even when the SFT loss looks good. Always compare base vs SFT on a few out-of-distribution prompts.
- Inconsistent response style. At toy data scale, style noise shows up directly in generations.
M-series notes¶
SFT is much less compute-hungry than pretraining — typically minutes, not hours.
- Total wall-clock estimates at
max_steps=500, on a Module-10-pretrained checkpoint:
┌────────┬────────────┬────────────┬────────────┐
│ size │ M1/M2 8GB │ M2 Pro 32GB│ M3 Max 64GB│
├────────┼────────────┼────────────┼────────────┤
│ 1M │ ~2 min │ ~1 min │ <1 min │
│ 5M │ ~5 min │ ~3 min │ ~2 min │
│ 30M │ ~15 min │ ~7 min │ ~5 min │
└────────┴────────────┴────────────┴────────────┘
The 30M model's SFT comfortably fits in a coffee-break window. Run it on the largest checkpoint you have — quality scales with base-model size, and SFT is cheap enough that there's no reason to start small.
- Memory. SFT memory cost is the same as pretraining training at the same
(B, T). No new tensors of meaningful size.
Reading¶
Primary:
- Ouyang, Wu, Jiang et al., "Training language models to follow instructions with human feedback" (InstructGPT, 2022). The paper that put SFT on the map. §3.4 has the SFT step. The paper bundles SFT with reward modeling and RLHF, but the SFT step alone produces 80% of the qualitative behavior change — a fact that the Alpaca paper made everyone realize.
- Stanford Alpaca blog post / repo (2023). The first popular small-scale SFT recipe — 52K self-instruct examples on Llama 7B, trained in three hours. The critical insight: SFT works at small scale and small budget. Read the blog; skim the repo.
- Zhou, Liu, Xu et al., "LIMA: Less Is More for Alignment" (2023). The data-quality paper. 1000 carefully-curated examples beat 52K crowd-sourced ones. The implication: SFT is teaching format, not facts; format can be taught from very few examples if those examples are consistent.
Secondary:
- Wang, Kordi, Mishra et al., "Self-Instruct" (2022). The synthetic-data pipeline that produced Alpaca's 52K examples — generate instructions and responses with a stronger model, filter for quality, train on the result. Mostly relevant when you want to scale SFT data without hand-authoring.
- Taori, Gulrajani, Zhang et al., "Stanford Alpaca: An Instruction-following LLaMA Model" (2023). The Alpaca paper's longer technical writeup, with the prompt template, training hyperparameters, and an ablation on dataset size.
- Chung, Hou, Longpre et al., "Scaling Instruction-Finetuned Language Models" (Flan-T5, 2022). The instruction-tuning scaling-laws paper. Relevant for "what happens at much larger scale than ours."
- OpenChat, Vicuna, WizardLM technical reports. Each presents a slightly different take on the SFT recipe; the diversity of approaches at the 7B-class scale is itself instructive.
Optional:
- Hu, Shen, Wallis et al., "LoRA: Low-Rank Adaptation of Large Language Models" (2021). The most-used parameter-efficient alternative to full SFT. Out of scope for this module; relevant whenever full fine-tuning isn't feasible.
- Dettmers, Pagnoni, Holtzman, Zettlemoyer, "QLoRA" (2023). LoRA on a 4-bit quantized base model — the recipe everyone uses for hobbyist-scale fine-tuning of 7B+ models in 2024–2025.
- The original ChatML spec (OpenAI's tokenizer documentation). The exact byte sequences for
<|im_start|>,<|im_end|>, etc., and the rationale for vocab-extension over text markers.
Deliverable checklist¶
- All tests in
tests/test_sft.pypass. - Hand-authored dataset of 50+ instruction-response pairs in
data/sft/instructions.json(or similar). - SFT'd checkpoint saved to disk, separate from the base checkpoint. The base checkpoint is preserved for re-runs and ablations.
- One paragraph on what the SFT'd model can do and what it can't.
- You can explain — out loud, without notes — what the chat template's role markers are, and what the asymmetry between user-turn-ends and assistant-turn-ends is.
- You can explain — out loud, without notes — why "data quality dominates data quantity" applies more strongly at toy scale than at production scale.
- You can explain — out loud, without notes — why an SFT'd model that confidently invents factual answers is not a training failure — it's a capability limit, and SFT alone can't fix it.