Module 00 — Prerequisite review¶
Question this module answers: What do I need back in cache before building the stack?

This is a fast review, not a remedial course. If these ideas are familiar but rusty, this module should put the right concepts back in working memory before the real course starts. If several sections feel new, pause here and use this page as a map for a longer fundamentals pass before starting the course.
Before you start¶
This module assumes you are already a competent programmer and have seen the math before. The goal is recall, not first exposure.
Math¶
- Algebraic manipulation. Rearranging formulas, reading subscripts, and following expressions with several variables.
- Derivatives. Single-variable derivatives, partial derivatives, and the chain rule.
- Vectors and matrices. Dot products, matrix multiplication, norms, and shape reasoning.
- Basic probability. Discrete distributions, expectations, probability mass over choices, logarithms, and sampling.
Computer science¶
- Functions and composition. The whole course treats models as large composed functions.
- Loops and state. Training loops, decode loops, and agent loops are all explicit loops with changing state.
- Graphs. Computational graphs in Module 01 are directed acyclic graphs; later attention maps are dense communication graphs over tokens.
- Memory locality. Why traversing memory sequentially is much faster than jumping around.
- GPU vs. CPU. Basic familiarity with what a GPU does and why it's used for parallel computation.
- Asymptotic complexity. Comfortable with "this is O(n³), this is O(n²)" and what that implies as
ngrows.
Programming¶
- Python. Classes, functions, list/dict basics, closures, operator overloads, imports, virtual environments, and reading stack traces.
- Testing. Running
pytest, using-x, and reading a failing test as a contract. - Numerical Python basics. Enough NumPy or PyTorch familiarity to read
.shape, use@, and understand that vectorized code runs outside the Python interpreter.
Why we start here¶
Module 01 starts by building scalar autodiff. That only feels enlightening if derivatives, the chain rule, and "a computation as a graph" are already close at hand. Module 02 immediately moves to tensors and matrix multiplication. Module 03 adds loss functions, mini-batches, and train/validation splits. From there the building blocks rapidly stack on top of one another.
This module narrows the prerequisite surface to the parts that will actually be used. It is intentionally incomplete as a math course. You are reviewing just enough to keep the early modules focused on the ideas under study instead of turning every exercise into prerequisite archaeology.
The big idea¶
Deep learning is the repeated optimization of a parameterized function:
examples + parameters
|
v
forward pass
|
v
predictions / logits
|
v
loss
|
v
backward pass
|
v
gradients
|
v
parameter update
Each prerequisite topic supports one piece of that loop:
- Linear algebra packs many scalar operations into tensor operations.
- Calculus explains how a loss produces gradients for every parameter.
- Probability explains why logits, softmax, cross-entropy, and perplexity are the right language for prediction.
- ML workflow keeps training measurements honest.
- PyTorch and tests provide the substrate after the from-scratch pieces have taught the underlying idea.
If you can trace one training step through that diagram, the rest of the course has a place to land.
Concepts to internalize¶
Linear algebra and shapes¶
A tensor is an array plus shape metadata. The shape is not decoration; it is the contract.
Common shapes in this course:
scalar ()
vector (D,)
matrix (M, N)
batch of vectors (B, D)
batch of token sequences (B, T)
token representations (B, T, C)
logits over vocabulary (B, T, V)
For language-model shapes, the letters usually mean:
Bis batch size: how many examples are processed at once.Tis sequence length: how many token positions are in each example.Cis channel or hidden size: how many numbers represent each token after lookup.Vis vocabulary size: how many distinct token IDs the tokenizer can produce.
An embedding table is a lookup table with shape (V, C): one row for each token ID, and one C-dimensional vector in each row. If token IDs have shape (B, T), looking up each ID returns token representations with shape (B, T, C). You do not need to know how embeddings are trained yet; for now, the important idea is that lookup adds the representation dimension C.
The central operation is matrix multiplication:
The inner dimensions match and disappear through summation; the outer dimensions remain. A linear layer is the same rule with a batch:
The bias b broadcasts across the batch dimension. Broadcasting means a size-1 or missing dimension is conceptually repeated without copying data. It is convenient, but it can also hide shape bugs, so get in the habit of writing expected shapes next to tensor code.
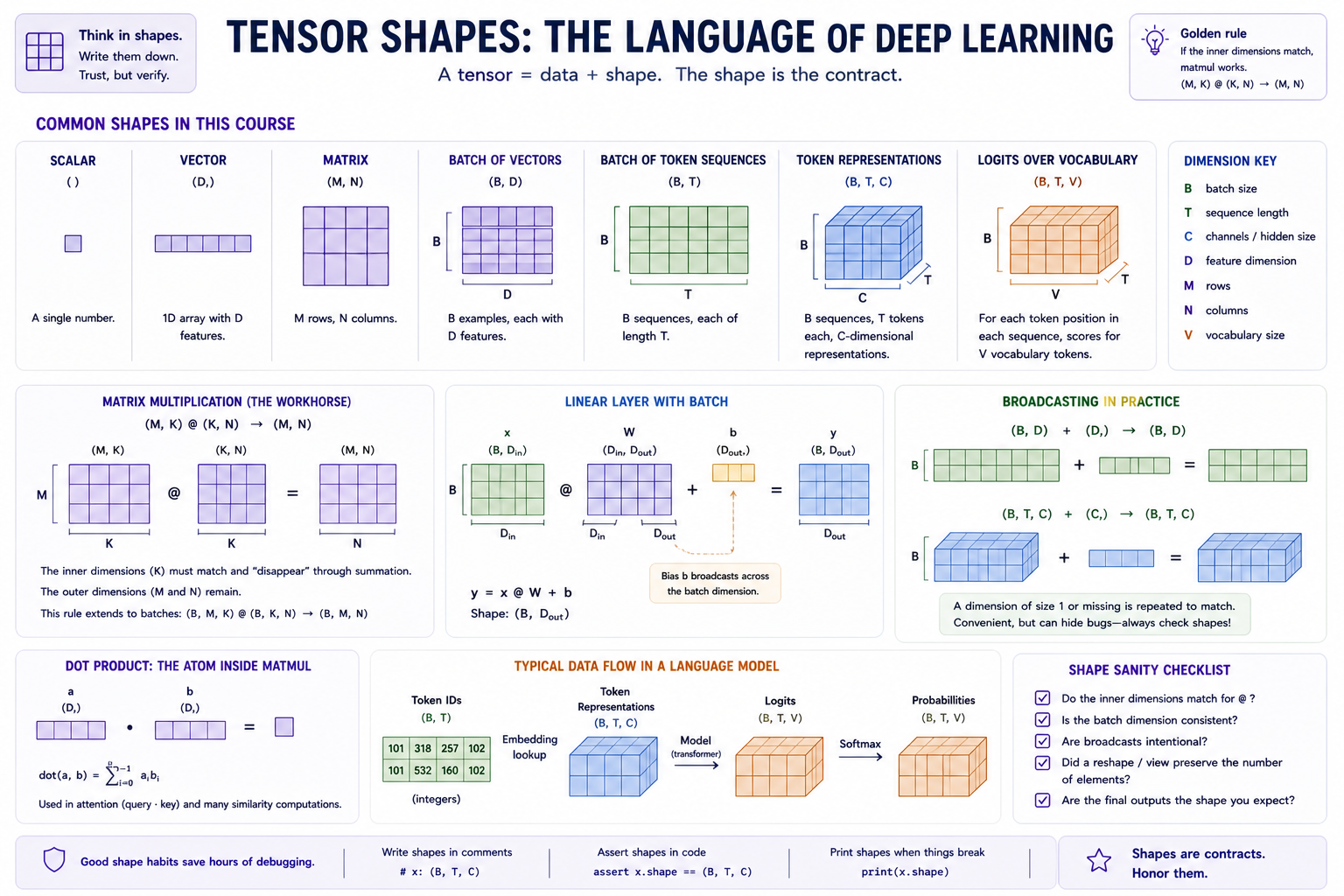
The shape vocabulary this course will reuse constantly. The same few contracts show up in linear layers, embeddings, attention, logits, and softmax; writing them down is the fastest way to catch a mistaken transpose, missing batch dimension, or accidental broadcast.
The dot product is the atom inside matmul:
Attention later uses dot products to ask "how compatible is this query with that key?" Embeddings use table lookup to turn discrete token IDs into vectors. Transformer blocks are mostly matmuls, broadcasts, elementwise nonlinearities, and reshapes.
A linear layer can also be read as a learned change of coordinates: it takes vectors written in one feature basis and projects them into another feature basis. You do not need a full course on eigenvectors or diagonalization here; just keep the "vectors move between representation spaces" picture available for embeddings, attention projections, and transformer blocks.
Before Module 02, you should be able to:
- Compute a small
2 x 3 @ 3 x 2matmul by hand. - Explain why
x @ W + bhas shape(B, D_out). - Read
(B, T, C)as batch, time, channels. - Notice when a broadcast is intended versus suspicious.
Calculus for backprop¶
For this course, a derivative is a local sensitivity: "if this input changes a little, how much does this output change?"
You need four ideas:
- Single-variable derivative.
d/dx x^2 = 2x. - Partial derivative. For
f(x, y) = x*y,df/dx = yanddf/dy = x. - Gradient. The vector of partial derivatives with respect to many inputs or parameters.
- Chain rule. If
Ldepends ona, andadepends onz, andzdepends onw, thendL/dw = dL/da * da/dz * dz/dw.
That is enough to understand backprop.
A one-neuron example:
The gradient with respect to w is:
The autodiff engine in Module 01 automates exactly this. Each operation stores a small local derivative rule. Backward traversal multiplies those local rules together along every path from loss back to parameter. If a value feeds multiple paths, its gradient is the sum of all path contributions.
Local derivatives worth having in cache:
d/dx (x + y) = 1
d/dy (x + y) = 1
d/dx (x * y) = y
d/dy (x * y) = x
d/dx (x^n) = n * x^(n - 1)
d/dx exp(x) = exp(x)
d/dx log(x) = 1 / x
d/dx tanh(x) = 1 - tanh(x)^2
d/dx relu(x) = 1 if x > 0 else 0
You do not need integration for this course's core path. You need local derivatives and the chain rule.
Probability, logits, and loss¶
Language models predict the next token by assigning a score to every possible token in the vocabulary. Those raw scores are logits. Logits are not probabilities: they can be negative, they do not sum to 1, and only their relative differences matter.
Softmax turns logits into a categorical distribution:
Subtracting max(z) is a numerical-stability trick. It does not change the probabilities, but it prevents exponentials from overflowing.
If the correct class is y, the negative log likelihood is:
Cross-entropy is the average negative log likelihood across examples. It is the default loss for classification and next-token prediction because it directly rewards assigning high probability to the observed target.
Perplexity is just cross-entropy put back on a multiplicative scale:

The prediction loop in probability language. A model emits logits, softmax turns them into probabilities, cross-entropy rewards probability on the true next token, and perplexity gives that loss a scale you can compare while training.
For language modeling, the dataset is text shifted by one position:
The model sees the inputs and is trained to predict the targets. Everything from bigrams to transformers uses this same objective.
ML workflow¶
The model is a function with parameters. Training repeatedly estimates how wrong the function is, computes gradients, and updates the parameters.
The basic supervised training loop:
for x, y in batches:
logits = model(x)
loss = cross_entropy(logits, y)
loss.backward()
optimizer.step()
optimizer.zero_grad()
The names will change as you build pieces from scratch, but the loop will keep this shape.
Key workflow concepts:
- Parameters. The learned numbers: weights, biases, embedding tables, projection matrices.
- Hyperparameters. The chosen settings: learning rate, batch size, model width, context length, number of layers.
- Training split. Data used to update parameters.
- Validation split. Data used to choose settings and notice overfitting.
- Test split. Data held back until you want a final estimate.
- Mini-batch. A small group of examples used to estimate a gradient step.
- Overfitting. Training loss improves while validation loss stops improving or gets worse.
- Learning rate. The step size. Too high can diverge; too low can make learning look broken.
The course's tiny models will fail in visible ways. That is useful. A small model that overfits, loops while sampling, or fails an eval is easier to understand than a giant model that hides the same failure modes behind fluent output.
Python, PyTorch, and repo mechanics¶
The course starts from scratch where the concept is the lesson, then uses PyTorch tensor primitives once scalar mechanics are established. You should be able to read small snippets like:
import torch
device = "mps" if torch.backends.mps.is_available() else "cpu"
x = torch.randn(32, 128, device=device)
W = torch.randn(128, 64, device=device)
y = x @ W
print(y.shape) # torch.Size([32, 64])
You do not need to know all of PyTorch. You do need:
torch.tensor,torch.randn,.shape,.dtype,.device@for matmul- elementwise arithmetic
- indexing and slicing
.to(device)torch.no_grad()for inference- enough autograd familiarity to know that
loss.backward()fills.grad
This course includes a PyTorch Primer that can be used both as an in-depth review focused on the PyTorch features used in this course and as a general reference.
Setup¶
Module 00 is a readiness review. However, it's a good idea to prepare your development environment for the rest of the course.
Run the setup script once:
That prepares the Python environment, the small TinyShakespeare corpus, and the smoke test. Larger datasets are optional and are not part of normal setup. If you want to preload the larger local data files used later in the course, run:
./datasets.sh --tiny # fastest local artifact path
./datasets.sh --small # recommended local course path
./datasets.sh # full/stretch local data path
You can also wait until a module asks for a dataset and download only that target, such as ./datasets.sh glove for Module 05 or ./datasets.sh tinystories for Module 10. TinyStories is stored as compressed text shards (~100MB uncompressed each). The script is idempotent, so repeated runs skip files and artifacts that are already present.
For the complete track guide, including download sizes, disk expectations, and heavy artifact-generation steps, read Course Tracks and Artifacts. To inspect what this checkout already has, run:
If feedback shows a weak spot, ask the agent for a few focused practice problems in chat. You can answer one, some, or all of them, and the agent should grade only what you attempt.
Exercises¶
Open the working notebook with ./notebook.sh 00 (or ./notebook.sh 00 --fresh to reset from the clean scaffold). The notebook has the exact prompts and Question: / Answer: cells. If you'd like a hint instead of a grade, write the request in the answer string and ask a coding agent for help. Blank answers are skipped rather than counted wrong.
- Shape trace. Follow token IDs through embedding lookup and projection to vocabulary logits.
- Matmul by hand. Compute a small matrix product and state the input/output shapes.
- Backprop by hand. Write one-neuron gradients as products of local derivatives.
- Softmax and loss. Convert small logits into probabilities and negative log likelihood.
- Training-loop narration. Explain
forward -> loss -> backward -> step -> zero_gradin a few sentences. - Environment check. Run
./setup.shand confirm the course environment is ready.
Pitfalls to expect¶
- Trying to relearn everything. The goal is not to master all prerequisite fields. It is to recover the pieces used by this course.
- Treating shapes as incidental. Shapes are the fastest debugging tool you have. Write them down.
- Confusing logits with probabilities. Logits become probabilities only after softmax.
- Forgetting gradient accumulation. If one value affects the loss through two paths, both contributions count.
- Using the test suite wrong. On scaffold branches, full-module tests are supposed to fail. Use the failing test names as implementation directives.
- Over-reading before coding. If you can do the exercises above, start Module 01. The course is designed to teach by building.
Reading¶
Primary refreshers:
- 3Blue1Brown, "Essence of Linear Algebra" - dot products, matrix multiplication, and transformations.
- 3Blue1Brown, "Backpropagation calculus" - the chain-rule picture behind autodiff.
- PyTorch official tutorial, "Tensors" - enough tensor mechanics for Module 02 onward.
- Karpathy, "The spelled-out intro to neural networks and backpropagation" - useful bridge into Module 01.
Optional:
- Parr and Howard, "The Matrix Calculus You Need For Deep Learning" - use as a reference, not as a prerequisite wall.
- Goodfellow, Bengio, Courville, Deep Learning, Chapters 5-6 - skim for terminology and loss-function context.
Deliverable checklist¶
- You can explain the training loop diagram without notes.
- You can trace simple tensor shapes through
x @ W + b. - You can compute a small matmul by hand.
- You can derive a one-neuron gradient with the chain rule.
- You can explain logits, softmax, cross-entropy, and perplexity.
-
./setup.shruns successfully, including its smoke-test step. - You know to use
pytest -xas the next directive while implementing.