Module 09B — Pretraining¶
Question this module answers: How do we learn from text?
Last week we built the transformer — a language model composed of stacked attention and neural networks. In terms of language model architecture, the transformer is the "final form". Every single major LLM in use today is built on top of the transformer. It will be the model we use for the remainder of the course.
The next step is turning the core architecture into an actual trained model. Training language models to even basic levels of competency requires vast scales of data and compute. There is no room for inefficiency in the process. This lesson will be about how to build an efficient and effective self-supervised learning pipeline on top of the transformer.
Before you start¶
- Review
- 03-nn on cross-entropy
- 09-transformer-block on logit shapes
- Finish packages:
g2c/transformer(09-transformer-block)g2c/nn(03-nn)g2c/training(03b-training)
Where this fits in¶
At the end of Module 09, TransformerLM.forward() returns logits shaped (B, T, V). That output is not useful until you can answer two questions:
- What exactly are the
(B, T)inputs and(B, T)targets? - How do those
(B, T, V)logits become one scalar loss?
Module 06 used a fixed context and one target:
A causal transformer gives you more signal. For one window of length T, it produces T next-token predictions in parallel:
Every position in x has a target in y. The causal mask makes this legal: when the model predicts y[t], it can see x[:t+1] but not the future token itself.
The big idea¶
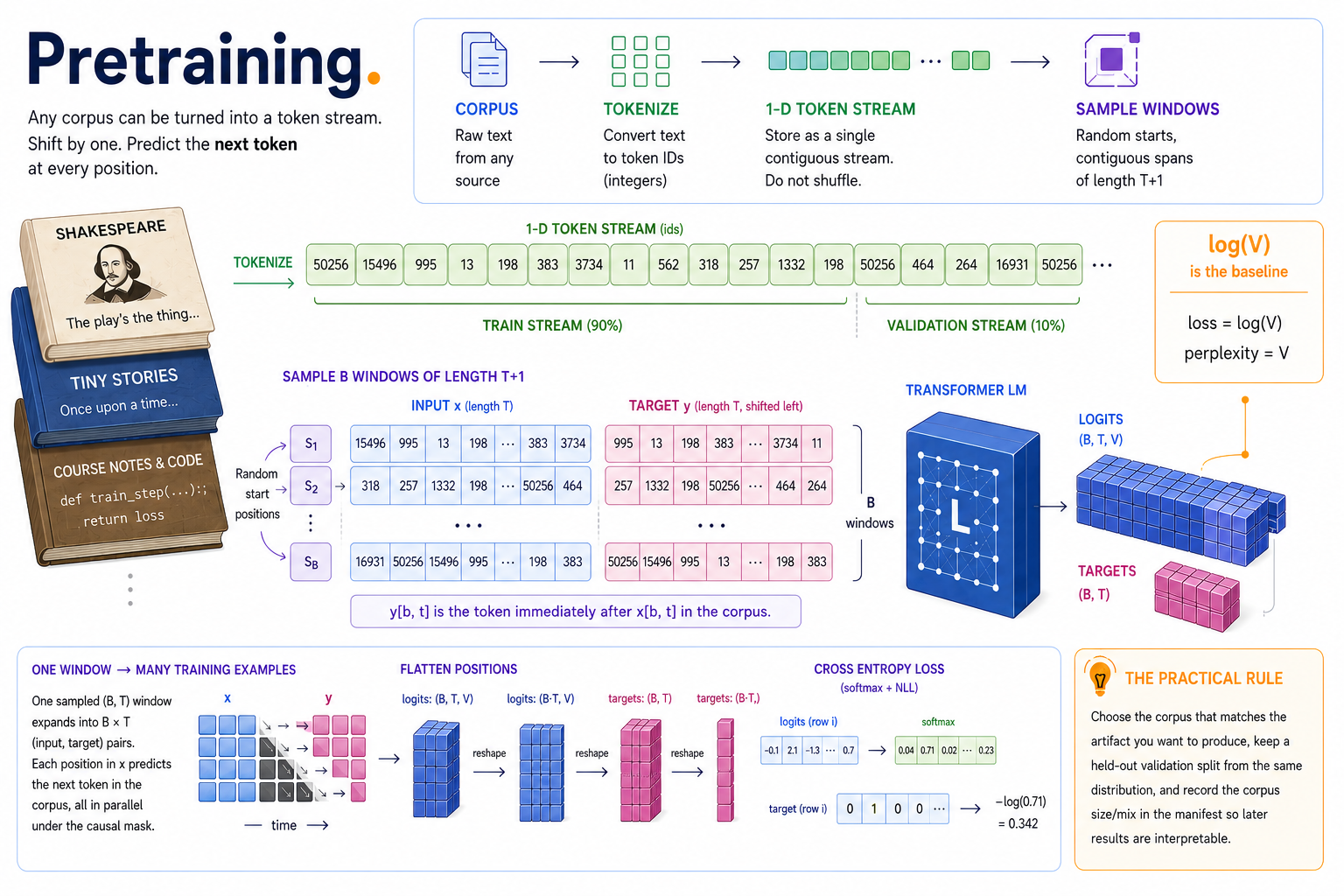
Any corpus can be turned into a token stream. Start with text, tokenize it, and store a single 1-D token stream:
Then split it contiguously:
Do not shuffle the individual token IDs. Shuffling would destroy the adjacency relation that next-token prediction depends on. The training stream and validation stream can each be sampled randomly by window, but each sampled window must preserve local order.
Batch sampling creates shifted windows¶
get_lm_batch samples B starting positions from a 1-D stream. Each start needs T + 1 contiguous tokens:
Stacking many windows gives:
The headline contract is simple:
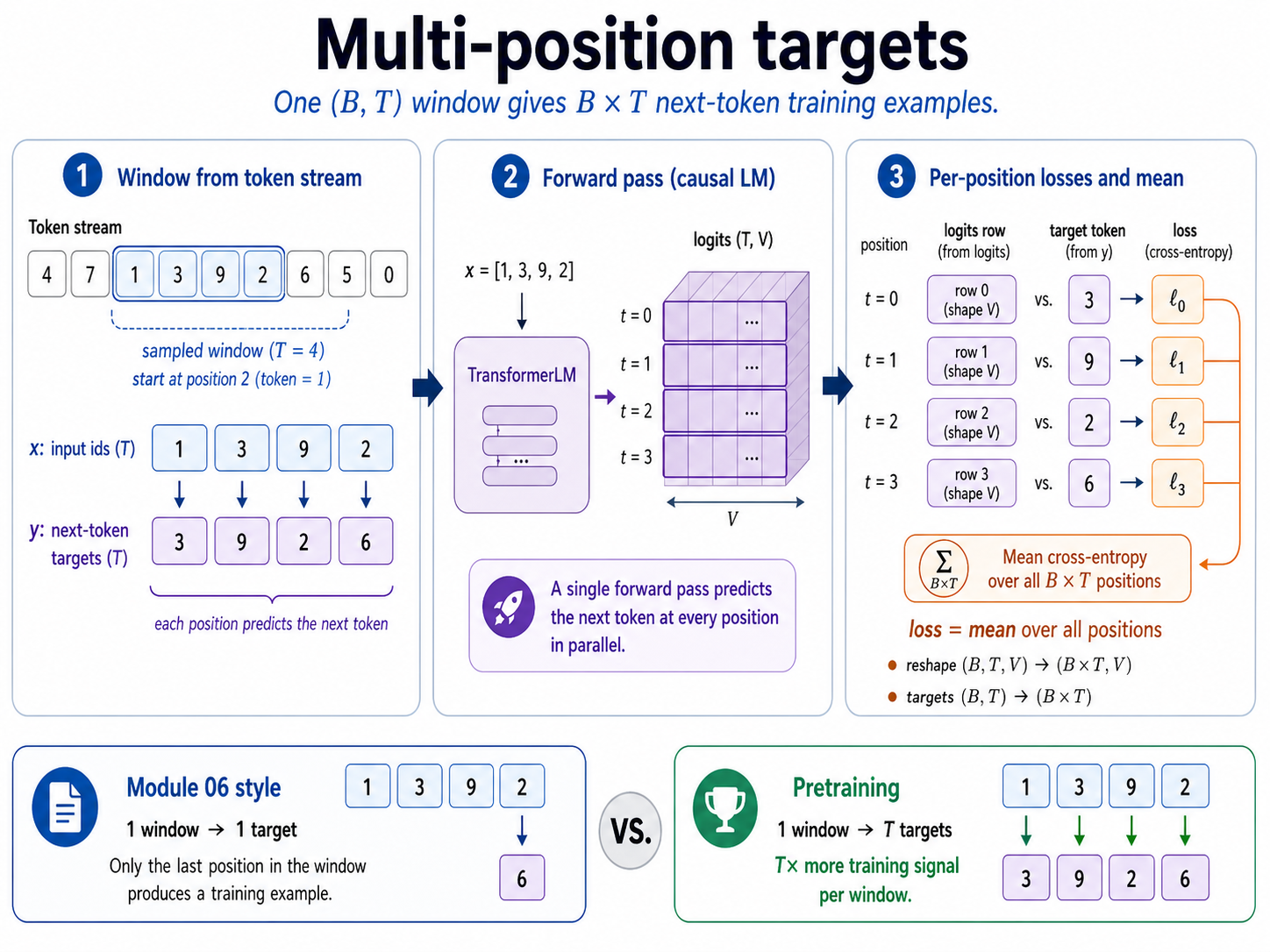 One contiguous stream sample becomes many supervised examples: every position predicts the token immediately after it. The causal mask is what makes this parallel training legal, because each position can use only its past and present inputs.
One contiguous stream sample becomes many supervised examples: every position predicts the token immediately after it. The causal mask is what makes this parallel training legal, because each position can use only its past and present inputs.
The loss flattens positions¶
TransformerLM(x) returns:
Your CrossEntropyLoss from Module 03 expects one row per classification example:
So lm_cross_entropy treats every (b, t) position as one example:
B, T, V = logits.shape
flat_logits = logits.reshape(B * T, V)
flat_targets = targets.reshape(B * T)
loss = CrossEntropyLoss()(flat_logits, flat_targets)
That is the pretraining objective in its smallest useful form: average next-token cross-entropy over every position in every sampled window.
log(V) is the sanity baseline¶
If all logits are zero, softmax is uniform over the vocabulary. Cross-entropy against a uniform distribution is:
At initialization, a random model's loss should usually start near log(V). If it starts far below log(V), suspect a bug: wrong targets, wrong reshape, repeated trivial data, or loading a trained checkpoint by accident. If it starts near log(V) and then drops, the model is learning.
Corpus selection is model behavior selection¶
The corpus is not just fuel for the optimizer. It is the behavior distribution the model is asked to imitate. TinyShakespeare teaches character names, stage directions, and Elizabethan fragments. TinyStories teaches simple narrative structure. A course corpus mixed with educational prose and code teaches a different shape again. Same architecture, same loss, different data: different model.
At small scale, corpus choice is especially visible because the model cannot average over the internet. A narrow corpus can produce more coherent samples inside its domain, but it will be brittle outside it. A broader corpus gives the model more surface area, but each pattern gets fewer repetitions for a fixed training budget. That is why Module 10 uses named tracks: ShakespeareLM for a tiny smoke run, StoryLM for coherent small-model text, and TinyLLM for broader assistant-shaped experiments.
Document boundaries also matter. If you concatenate stories or articles without a separator, the model sees the last sentence of one document followed by the first sentence of the next as an ordinary next-token event. The course tokenizer reserves <|endoftext|> so document boundaries can be represented explicitly. Sampling code should avoid crossing documents when possible; when it does not, the separator at least gives the model a visible boundary token.
The practical rule for this course: choose the corpus that matches the artifact you want to produce, keep a held-out validation split from the same distribution, and write down the corpus size/mix in the manifest so later results are interpretable.
Concepts to internalize¶
- A token stream is supervised data once you shift it by one.
- Document separators are training data.
<|endoftext|>tells the model one document ended before another begins. - Causal masking makes multi-position training valid. Every position predicts the next token without seeing it.
- One
(B, T)batch containsB * Tclassification examples. - Language-model cross-entropy is ordinary cross-entropy after a reshape.
log(V)is not transformer-specific. It is the uniform baseline for any language model with vocabulary sizeV.- Corpus choice shapes model behavior. Data distribution matters as much as architecture at this scale.
What we don't cover¶
- Distributed training. Used to scale large-scale training beyond a single machine. Lots of devops considerations, but conceptually just an extension of gradient batching.
- Mixed precision. Speeds up training by using lower-precision floats for most operations and selectively keeping high precision for load-bearing weights.
- Packed datasets. Combines multiple short training sequences into a single long sequence. Avoids wasting compute on padding.
What you'll build¶
Package: g2c/pretraining/
def split_token_stream(
ids: torch.Tensor,
train_fraction: float = 0.9,
) -> tuple[torch.Tensor, torch.Tensor]: # implemented
def get_lm_batch(
ids: torch.Tensor,
batch_size: int,
context_length: int,
*,
generator: torch.Generator | None = None,
) -> tuple[torch.Tensor, torch.Tensor]: # implemented
def lm_cross_entropy(
logits: torch.Tensor,
targets: torch.Tensor,
) -> torch.Tensor: # SCAFFOLDED
split_token_stream and get_lm_batch are implemented for you. lm_cross_entropy is the one scaffolded function — it reshapes (B, T, V) logits and (B, T) targets, then calls your Module 03 CrossEntropyLoss.
How to run the tests¶
Tests live in tests/test_pretraining_setup.py. Initial state: 10 passed, 5 failed. The data.py tests pass from the start; lm_cross_entropy tests fail until you implement the reshape.
source .venv/bin/activate
pytest tests/test_pretraining_setup.py -x
pytest tests/test_pretraining_setup.py -v
Exercises¶
To launch the exercise notebook run:
If at any point you want to archive the work in your current notebook and restart fresh:
Each exercise has Question: / Answer: cells inside the notebook. If you'd like a hint instead of a grade, write the request in the answer string and ask a coding agent for help. Blank answers are skipped rather than counted wrong.
- Shift a toy stream. Write
xandyfor a tiny next-token window. - Causal mask reasoning. Explain why multi-position training needs masking.
- Inspect
get_lm_batch. Verify sampled inputs and targets are shifted by one token. - Implement
lm_cross_entropy. Flatten sequence logits/targets and run the tests. - Flatten shapes. Count how many classification examples a
(B, T, V)batch contains. - Compute
log(V). Use the uniform baseline to sanity-check initial loss. - Random-model check. Compare a tiny transformer's initial loss to
log(V).
Pitfalls to expect¶
- Off-by-one targets.
ystarts one token afterx. Ify == x, the model is learning to copy the current token, not predict the next one. - Sampling past the end. Each window needs
T + 1tokens, not justT. - Shuffling tokens. Shuffle windows if you want randomness, not individual token IDs.
- Flattening one tensor differently than the other.
logits.reshape(B * T, V)andtargets.reshape(B * T)must preserve the same(B, T)order. - Reading
log(V)as failure. At step 0,log(V)is the expected baseline. The interesting question is whether the curve drops below it.
M-series notes¶
This module is CPU-light. The tensors are tiny, and no serious training run happens yet. MPS matters again in Module 10, where the same helpers sit inside thousands of optimizer steps.
Reading¶
- Karpathy, nanoGPT, especially the
get_batchand loss computation. - Karpathy, "Let's reproduce GPT-2 (124M)", the data-loader and training-loop sections.
- Vaswani et al., "Attention Is All You Need", causal masking and parallel sequence training context.
Deliverable checklist¶
-
pytest tests/test_pretraining_setup.pypasses. - Notebook:
notebooks/solutions/09b-pretraining.ipynb. - You can explain why one
(B, T)batch containsB * Tnext-token prediction examples. - You can implement
lm_cross_entropyfrom the shape contract alone. - You can use
log(V)as a step-0 sanity check before a Module 10 training run.